While significant resources have been allocated to enhance the safety of large language models (LLMs) for deployment, safety of multilingual LLMs remains underexplored (Yong et al., 2023a; Deng et al., 2024). Recent work has shown that multilingual LLMs have significant toxicity levels and therefore highlights the need for multilingual toxicity mitigation (Jain et al., 2024). However, to reduce toxicity in open-ended generations in a nonEnglish language X, current solutions (Pozzobon et al., 2024; Liu et al., 2021; Pozzobon et al., 2023; Dementieva et al., 2024) are resource-intensive as they require datasets of toxic and non-toxic samples in the language X, which is usually obtained through translating from English data (Pozzobon et al., 2024; Dementieva et al., 2024) due to resource unavailability.
In this work, we study cross-lingual detoxification of LLMs using English preference tuning without translation. While prior work suggests limited cross-lingual transfer of preference tuning for the task of safeguarding against malicious instructions (Yong et al., 2023a; Shen et al., 2024; Wang et al., 2023; Deng et al., 2024), we discover the opposite for LLM detoxification task— we demonstrate zero-shot cross-lingual generalization of preference tuning in lowering toxicity of open-ended generations. Specifically, we observe preference tuning with Direct Preference Optimization (DPO) (Rafailov et al., 2023) using only English training data can significantly reduce the toxicity level in LLMs’ generations across 17 different languages, such as Chinese, Arabic, Korean, Russian and Indonesian. Our findings apply to multilingual LLMs of different sizes and with different pretraining composition, including mGPT (Shli- azhko et al., 2024), Llama3 (AI@Meta, 2024), and Aya-23 (Aryabumi et al., 2024). 1
We investigate the mechanisms enabling cross-lingual generalization of safety preference tuning. Recent work (Lee et al., 2024) shows that models trained via DPO do not lose the ability to generate toxic content; instead, they learn to suppress the neuron activations that lead to toxicity, focusing on the role of key and value vectors in Multi-Layer Perceptrons (MLP). While these findings explain DPO’s effectiveness in the training language, they do not address its cross-lingual generalization. To bridge this gap, we extend the analysis to a multilingual context, and we demonstrate that both key
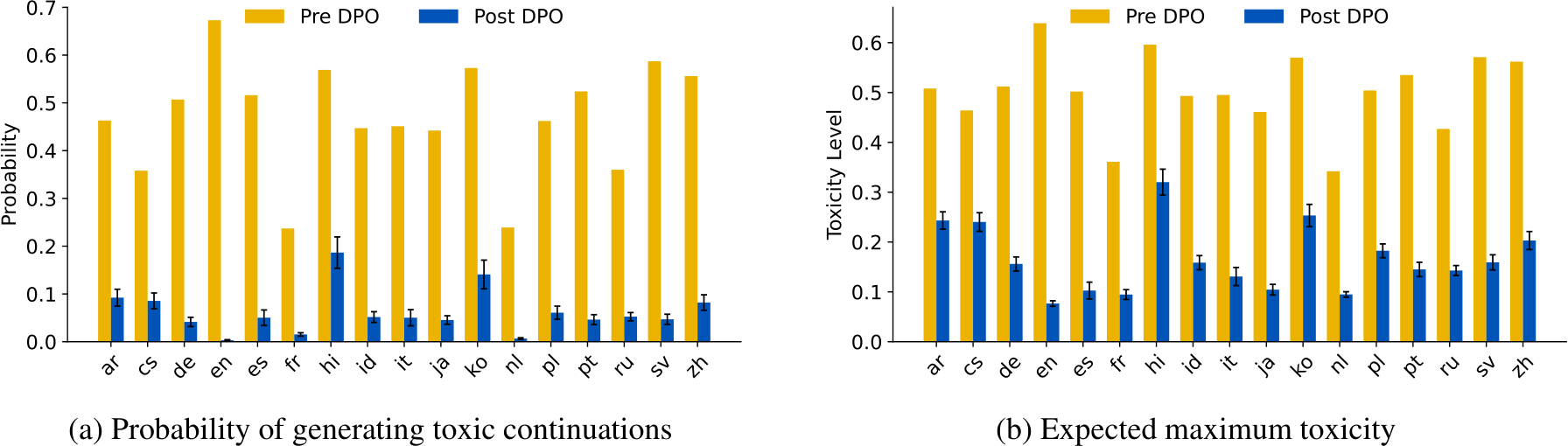
Figure 1: Safety preference tuning on English (en) pairwise toxic/non-toxic data reduces mGPT’s (Shliazhko et al., 2024) probability in generating toxic continuations (1a) and the expected toxicity level in its most-toxic generations (1b) across 17 different languages. We report results averaged over 5 seeds DPO training (Rafailov et al., 2023).
vectors and value vectors possess multilingual attributes, which we called the dual multilinguality of MLP. Value vectors encode multilingual toxic concepts, and their activations by key vectors promote tokens associated with these concepts across multiple languages, which indicates the multilingual nature of the key vectors. Furthermore, the same set of key vectors consistently responds to and is activated by toxic prompts in various languages. Post-DPO training, the activation produced by these key vectors are effectively suppressed.
Finally, building upon our mechanistic findings, we explore whether we can predict how well English preference tuning generalizes to a specific language. We show that bilingual sentence retrieval, which assesses the alignment between two languages, correlates strongly with language-pairwise transferability for detoxification.
Our contributions can be summarized as below:
1. This is the first work to demonstrate that preference tuning for toxicity mitigation can generalize cross-lingually in a zero-shot manner.
2. We demonstrate the dual multilinguality property of MLPs and explain the mechanism behind the cross-lingual generalization.
3. We show that cross-lingual detoxification with preference tuning strongly correlates with bilingual sentence retrieval accuracy.
Cross-lingual generalization of RLHF/RLAIF Prior work suggests that zero-shot cross-lingual generalization of preference tuning with reinforcement learning with human feedback (RLHF) (or with AI feedback, RLAIF) may be task-specific. For question-answering (QA), preference tuning of LLMs on English-dominant training data hurts its multilingual QA capability (Ivison et al., 2023), and thus multilingual training data are needed (Lai et al., 2023; Ryan et al., 2024). In contrast, for summarization, concurrent work demonstrates zero-shot cross-lingual generalization of RLHF with English reward models (Wu et al., 2024).
Similar findings apply to LLM safety research. For the task of developing safeguards against malicious instructions, there is limited zero-shot cross-lingual generalization to both low-resource (Deng et al., 2024; Yong et al., 2023a; Shen et al., 2024) and high-resource languages like Chinese (Shen et al., 2024). Here, we focus on another safety task, which is toxicity mitigation in open-ended generation (Gehman et al., 2020). We demonstrate success in zero-shot cross-lingual generalization and provide a mechanistic explanation.
Multilingual toxicity evaluation and mitigation Jain et al. (2024) and de Wynter et al. (2024) release multilingual toxicity evaluation benchmarks and they show that model toxicity increases as language resources decrease. To mitigate multilingual toxicity, current solutions (Pozzobon et al., 2024; Dementieva et al., 2024) require translating toxic and non-toxic data from English to target languages in order to extend existing detoxification methods (Liu et al., 2021; Pozzobon et al., 2023) to multilingual settings. Dementieva et al. (2023) also find limited zero-shot cross-lingual detoxification for supervised finetuning with models like M2M100 (Fan et al., 2021). In contrast, we demonstrate cross-lingual detoxification with only English training data across different multilingual LLMs.

Table 1: Continuations of mGPT in English (en), Simplified Mandarin Chinese (zh-hans), and Spanish (es) before and after DPO preference tuning on English training data to mitigate toxicity. The input prompts here are human translations of the en prompt and are taken from RTP-LX (de Wynter et al., 2024).
In concurrent work, Jain et al.’s (2024) toxicity benchmark shows that preference-tuned LLMs have lower multilingual toxicity, but it only studies variants of the Llama2 (Touvron et al., 2023) that are finetuned on large and diverse preference data such as Anthropic HH (Bai et al., 2022) and UltraFeedback (Cui et al., 2023). Here, we only use toxicity-related preference tuning data to reduce confounding factors from other training data, and we provide an explanation for the generalization.
Safety-specific regions in LLMs Prior work has shown that we can isolate and manipulate neurons to control the safety behaviors of LLMs (Wei et al., 2024; Bereska and Gavves, 2024; Belrose et al., 2024; Wang et al., 2024b; Arditi et al., 2024; Zou et al., 2024). Geva et al. (2021, 2022) identify specific neurons in MLP layers that facilitate the prediction of tokens associated with concepts such as toxicity. Balestriero et al. (2023) also show that the geometrical spline features in MLP layers can be used to classify between toxic and non-toxic inputs, indicating the toxicity representations in LLMs. Lee et al. (2024) reveal that DPO detoxifies models by avoiding activating neurons associated with toxicity, and Uppaal et al. (2024) show that we can detoxify models by projecting model weights out of the latent toxic subspace. However, little work has been done on characterizing multilingual toxicity on the neuron level, albeit recent mechanistic study on cross-lingual generation for knowledge editing and sequence modeling (Wang et al., 2024a; Hua et al., 2024). Here, we demonstrate the multilingual nature of the toxic subspace. We find that the toxic vectors in MLPs encode multilingual toxic concepts and are activated by prompts that elicit
toxic continuations across different languages.
We follow Lee et al.’s (2024) setup to perform preference tuning on LLMs for LLM detoxification. Specifically, we perform Direct Preference Optimization (DPO) (Rafailov et al., 2023) with Lee et al.’s (2024) preference dataset that consists of 24,576 instances of prompts as well as pairs of toxic (dispreferred) and non-toxic (preferred) continuations in English.
We finetune five different base LLMs: (1) mGPT, a multilingual GPT with 1.3B parameters (Shli- azhko et al., 2024); (2) BLOOM, a multilingual language model with 1.7B and 7.1B parameters (BigScience Workshop et al., 2022); (3) Aya-23, a multilingual language model with 8B parameters (Aryabumi et al., 2024); (4) Llama2-7B (Touvron et al., 2023); and (5) Llama3-8B (AI@Meta, 2024). We perform full finetuning for mGPT and BLOOM-1.7B, and we use QLoRA adapters (Dettmers et al., 2023) for finetuning models at 7B and 8B parameter sizes.
We use HuggingFace trl library and follow Lee et al.’s (2024) hyperparameters (except learning rate) for full model finetuning of mGPT and BLOOM-1.7B. For QLoRA finetuning of Aya-23, LLama2, and Llama3, we apply QLoRA (Dettmers et al., 2023) on each model layer, with a rank of 64, a scaling parameter of 16 and a dropout of 0.05. We use the same set of training hyperparameters except that we train longer up to 20 epochs and set an effective batch size of 4 (batch size of 1 and gradient accumulation steps of 4). In all setups, we use early stopping by training until the validation loss
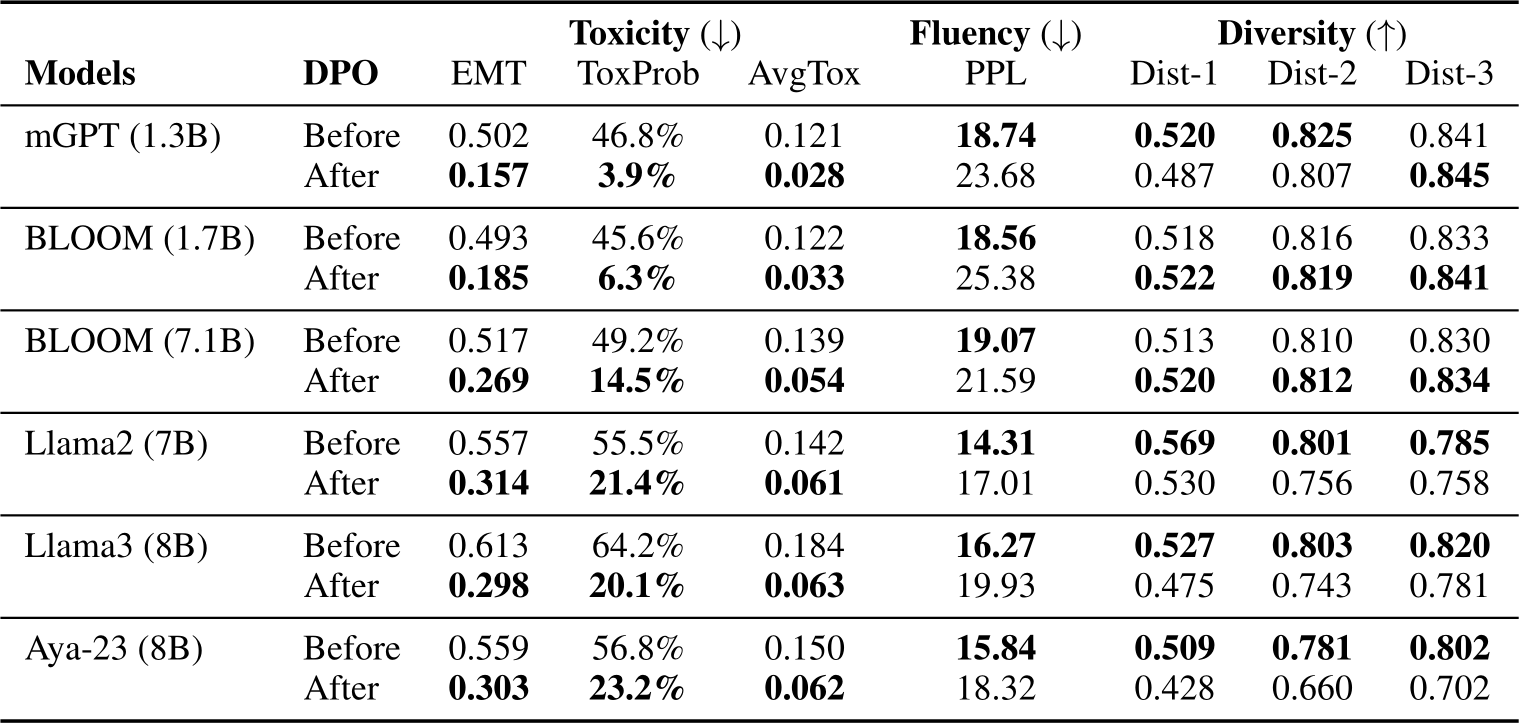
Table 2: Average scores in toxicity, fluency and diversity in model continuations on RTP-LX (de Wynter et al., 2024) input prompts across 17 different languages before and after English DPO preference tuning (Rafailov et al., 2023).
converges with a patience value of 10. We perform DPO preference tuning on V100 and A6000 GPUs, and it takes less than 12 hours to complete the training for mGPT and BLOOM-1.7B and around 24 hours to complete the training for Aya-23, Llama2 and Llama3 (see Table 6 for further details on hyperparameters.)
3.1 Multilingual Toxicity Evaluation
3.1.1 Evaluation dataset
We use multilingual toxic prompts from RTP-LX benchmark (de Wynter et al., 2024) to elicit toxic outputs from LLMs across 17 languages. RTP-LX consists of around 1,000 multilingual prompts either professionally translated from the English RTP dataset (Gehman et al., 2020) or hand-crafted to elicit culturally-specific toxic model continuations in a particular language. We choose the 17 languages that are supported by our toxicity evaluator Perspective API (Lees et al., 2022).
Following prior work (Gehman et al., 2020; Poz- zobon et al., 2024), we prompt LLMs to generate 25 samples (k = 25) of continuations of 20 tokens for each prompt, and we apply nucleus sampling (Holtzman et al., 2020) with a temperature of 0.9 and top-p probability of 0.8.
3.1.2 Metrics
We follow prior work (Pozzobon et al., 2024; Gehman et al., 2020; Üstün et al., 2024) in evaluating the effectiveness of multilingual detoxification. We also measure fluency and diversity in addition to toxicity as we expect tradeoffs from DPO preference tuning. Furthermore, we evaluate model’s mul- tilingual capabilities on Multilingual ARC (Clark et al., 2018), Multilingual Hellaswag (Zellers et al., 2019), and Multilingual MMLU (Hendrycks et al., 2020) after preference tuning following Lai et al. (2023).
Toxicity We score the toxicity of model continuations with Perspective API (Lees et al., 2022). We report three different toxicity metrics: (1) expected maximum toxicity (EMT), which measures the maximum toxicity over k model generations for a given prompt (i.e., expected toxicity level in the most-toxic generation) (2) toxicity probability (ToxProb), which measures the probability of the model generating toxic continuations2 at least once among k generations; and (3) average toxicity (AvgTox) for all sampled model continuations.
Fluency We measure fluency by scoring the perplexity of the continuations conditioned on the prompts using the multilingual mT5-XL model (Xue et al., 2021). A lower perplexity indicates a more fluent and coherent output. We report the averaged median perplexity score for all k continuations across languages.3
Diversity We measure the diversity of continuations for each prompt using the proportion of distinct n-grams. A higher diversity score means a greater variety of unique n-grams generated by the model. We report the diversity scores for unigrams, bigrams, and trigrams (Dist-1, Dist-2, and Dist-3, where “Dist” denotes “Distinct”).
3.2 Results
Figure 1 and Table 2 demonstrate zero-shot cross-lingual transfer of toxicity mitigation. Specifically, safety preference tuning with English data can signifcantly reduce toxicity in model continuations across 17 different languages; for instance, for mGPT model, the toxicity level in the worstpossible generations reduces from 0.502 to 0.157 and the probability of generating one toxic output reduces from 46.8% to 3.9%. Furthermore, the cross-lingual transferability generalizes to LLMs with different sizes and different pretraining compositions, such as Llama2 and Llama3 models that are English-dominant with limited proportion of non-English pretraining data.
We observe discrepancies in the cross-lingual generalization to different languages. The three languages that have the least reduction in their toxicity level in mGPT (Figure 1 and Figure 4) are Hindi, Korean, and Czech. Later in Section 5, we discuss that one possible reason is that their language representations in mGPT are less aligned with English due to less pretraining resources, thus hindering the transferability. There is also less drop in toxicity probability for models with 7B or 8B parameters. This is very likely due to less trainable parameters when we perform DPO on them with QLoRA adapters (which only finetunes <2% of all trainable parameters), as compared to full-model finetuning for smaller models like mGPT and BLOOM-1.7B (see Appendix D for QLoRA training for BLOOM-1.7B).
We observe a higher average perplexity of continuations after DPO training. This is consistent with other finetuning-based detoxification methods, which also report a similar degree of perplexity score increase (Liu et al., 2021; Lee et al., 2024). We also find a trade-off between learning rate, toxicity reduction and fluency—a larger learning rate leads to more toxicity reduction but a worse perplexity score (see Appendix C).
Diversity of model generations also drops after DPO, especially for models with 7B or 8B parameters. This is consistent with prior findings that RLHF algorithms reduce output diversity in other English NLP tasks such as summarization (Khal- ifa et al., 2021; Kirk et al., 2024) where RLHF biases the models towards outputing text of a specific style. Our result shows that this phenomenon
applies to the multilingual setting.
In addition, we show little degradation on model’s multilingual capability after DPO preference tuning in Table 3. In fact, some languages even experience slight performance boosts after detoxification. Due to compute constraints, we only tested on BLOOM-7B1 model on four languages on multilingual ARC, HellaSwag, and MMLU datasets (Lai et al., 2023).
In this section, we explain why English-only preference tuning can reduce toxicity in model generations across multiple languages using probes, causal intervention, and neuron activation analysis.
4.1 Preliminaries
We adopt the residual stream perspective of transformer blocks (Elhage et al., 2021) and the framework of MLPs being key-value memory retrieval systems (Geva et al., 2021).
Residual stream The residual stream, also known as embedding, for a token at layer ![]() , denoted as
, denoted as 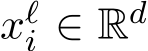 , is propagated through residual connections (He et al., 2016). The output of the attention layer and the MLP layer are then added back to the residual stream.4
, is propagated through residual connections (He et al., 2016). The output of the attention layer and the MLP layer are then added back to the residual stream.4
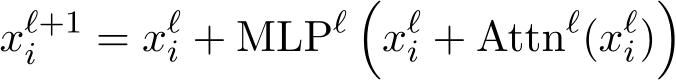
The additive nature of the residual stream view allows us to evaluate the contribution of different components separately. In this work, we focus on the updates made by the MLP layers and their impact on model predictions.
MLP as key-value vectors The MLP layers typically consist of two trainable weight matrices: 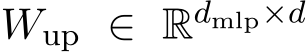 , which projects the intermediate residual stream to a higher-dimensional space, and
, which projects the intermediate residual stream to a higher-dimensional space, and 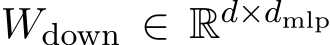 , which projects the highdimensional vector back to the original space. The
, which projects the highdimensional vector back to the original space. The ![]() is delineated by:
is delineated by:
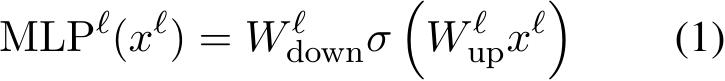
in which ![]() denotes the element-wise non-linear activation function. Equation (1) can be further
denotes the element-wise non-linear activation function. Equation (1) can be further

Table 3: Evaluation of multilingual capability of BLOOM-7B1 before and after English DPO training.
decomposed as 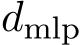 individual sub-updates:
individual sub-updates:
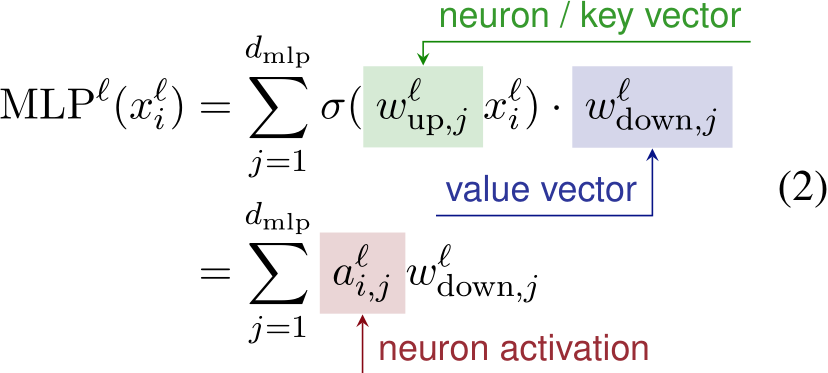
where 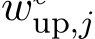 and
and 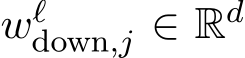 represent the j-th row of
represent the j-th row of 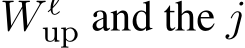 -th column of
-th column of 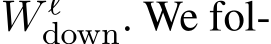 low previous literature (Geva et al., 2022; Lee et al., 2024) and call them the key vectors and value vectors of MLP respectively. We also denote each
low previous literature (Geva et al., 2022; Lee et al., 2024) and call them the key vectors and value vectors of MLP respectively. We also denote each 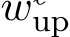 as a neuron, which can be considered a pattern detector (Ferrando et al., 2024). Each neuron yields a positive neuron activation
as a neuron, which can be considered a pattern detector (Ferrando et al., 2024). Each neuron yields a positive neuron activation 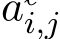 following the acti- vation function if its inner product with
following the acti- vation function if its inner product with 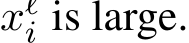 This activation subsequently scales
This activation subsequently scales 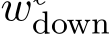 . There- fore, an MLP output can be interpreted as a linear combination of the columns of
. There- fore, an MLP output can be interpreted as a linear combination of the columns of 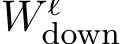 , weighted by their respective neuron activations.
, weighted by their respective neuron activations.
To obtain human-understandable interpretation of individual MLP sub-update, we can project its value vector from the embedding space to the vocabulary space using the unembedding matrix 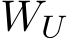 and get an unnormalized distribution over all tokens (Hanna et al., 2024; nostalgebraist, 2020). This tells us the tokens it promotes when its corresponding neuron is activated (Geva et al., 2022).
and get an unnormalized distribution over all tokens (Hanna et al., 2024; nostalgebraist, 2020). This tells us the tokens it promotes when its corresponding neuron is activated (Geva et al., 2022).
4.2 Methods
Localizing toxicity with probes To find and interpret toxic value vectors, we follow Lee et al. (2024) and train an English linear probe 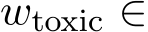
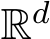 for binary toxicity classification. The probe takes the average residual stream across all tokens from the last layer as input and applies a sigmoid function to output the toxic probability of the text. In particular, we train the probe using the 90% of the training split of the Jigsaw dataset (cjadams et al., 2017) that comprises 15,294 toxic comments and 144,277 non-toxic comments. The probe achieves a validation accuracy of 94.31% on the remaining 10% held-out dataset and ROC-AUC (Receiver Operating Characteristic - Area Under the Curve) score of 0.862 on the test split of Jigsaw dataset. See Table 7 for more details on training hyperparameters.
for binary toxicity classification. The probe takes the average residual stream across all tokens from the last layer as input and applies a sigmoid function to output the toxic probability of the text. In particular, we train the probe using the 90% of the training split of the Jigsaw dataset (cjadams et al., 2017) that comprises 15,294 toxic comments and 144,277 non-toxic comments. The probe achieves a validation accuracy of 94.31% on the remaining 10% held-out dataset and ROC-AUC (Receiver Operating Characteristic - Area Under the Curve) score of 0.862 on the test split of Jigsaw dataset. See Table 7 for more details on training hyperparameters.
We rank all value vectors by their cosine similarity to the probe 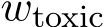 , and identified the top 100 vectors. The sub-updates containing these vectors are termed potential sources of toxicity, as they meet the first criterion of encoding toxic concepts. To identify the sub-updates that actually contribute to toxic generation, we collect the average neuron activations from the potential source of toxicity over the next 20 tokens using English prompts from the RTP-LX dataset (de Wynter et al., 2024). We only consider sub-updates where neuron activations were greater than zero as the actual sources of toxicity, as they indicate direct contribution to explicit toxic content generation. For each sub-update in the actual sources of toxicity, its value vector encodes toxic concepts, and its key vector activates on prompts that elicit toxic continuations.
, and identified the top 100 vectors. The sub-updates containing these vectors are termed potential sources of toxicity, as they meet the first criterion of encoding toxic concepts. To identify the sub-updates that actually contribute to toxic generation, we collect the average neuron activations from the potential source of toxicity over the next 20 tokens using English prompts from the RTP-LX dataset (de Wynter et al., 2024). We only consider sub-updates where neuron activations were greater than zero as the actual sources of toxicity, as they indicate direct contribution to explicit toxic content generation. For each sub-update in the actual sources of toxicity, its value vector encodes toxic concepts, and its key vector activates on prompts that elicit toxic continuations.
Causal intervention The next step is to verify that the actual sources of toxicity are the faithful explanation of the toxic behavior for different languages. We conducted causal intervention 5 by editing the neuron activations and evaluating changes in toxicity of generations across languages. Ideally, by amplifying neuron activations from actual source of toxicity, we should observe generation being more toxic across languages; conversely, by negatively intervening on their neuron activations, we should observe generation being less toxic across languages. Formally, for a set of selected neuron activations A, we directly edit them by changing their values 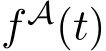 by adding an offset
by adding an offset ![]() to each individual activation
to each individual activation ![]() during the forward pass on input token t.
during the forward pass on input token t.
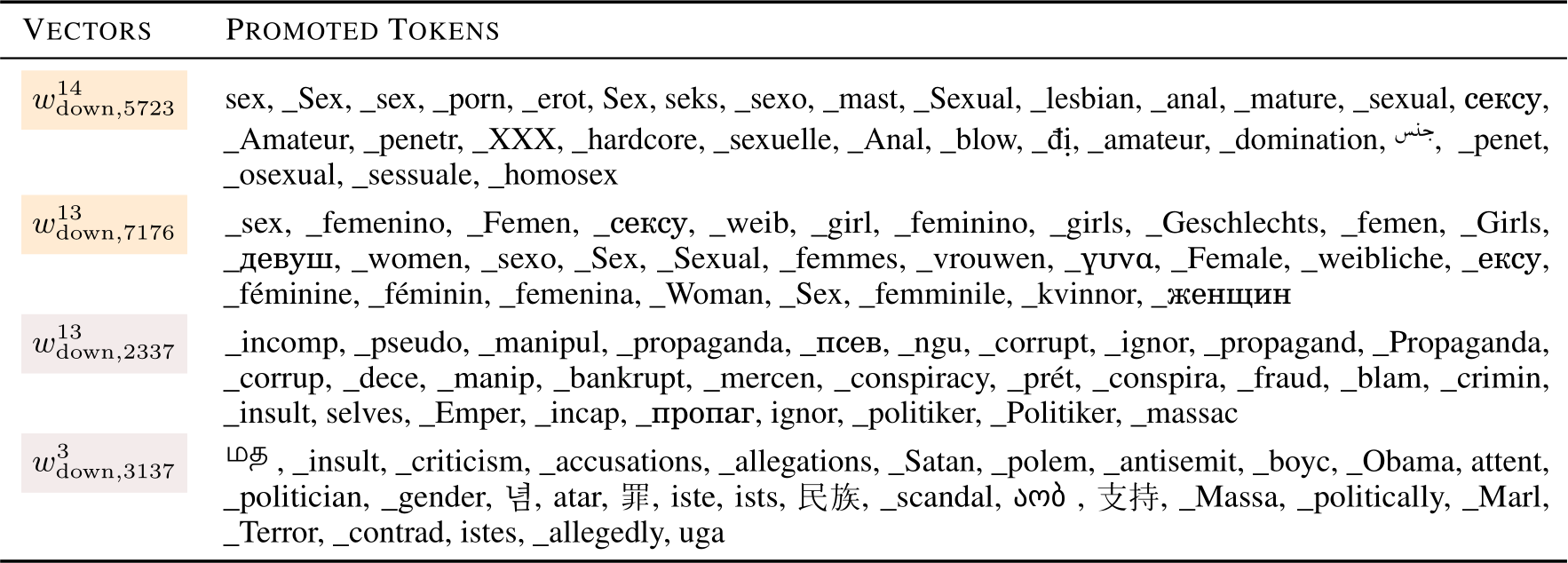
Table 4: Projection of 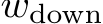 vectors onto vocabulary spaces. We display the top 30 promoted tokens for each selected projection. 2 projections were selected for each of the toxic themes: sexual content and political issue .
vectors onto vocabulary spaces. We display the top 30 promoted tokens for each selected projection. 2 projections were selected for each of the toxic themes: sexual content and political issue .
Activation analysis It is natural to ask whether the actual sources of toxicity, identified using English prompts, are consistent across languages. We analyze the average neuron activations of these sources over the next 20 tokens following input prompts in 17 languages, using the RTP-LX dataset (de Wynter et al., 2024). If the neuron activations before DPO training are consistently activated across different languages, this means that these neurons or key vectors are inherently multilingual. Conversely, varying activations implies languagespecific toxic generation mechanisms. Furthermore, reduced neuron activations across languages after DPO would confirm detoxification through the suppression of the same set of neurons.
4.3 Results
Our experiments demonstrate dual multilinguality of MLP: value vectors in MLP are multilingual as they consistently promote toxic tokens of the same concept across various languages, and key vectors respond to multilingual input prompts that are curated to elicit toxic continuations. All experiment results in Section 4.3 are with mGPT (Shliazhko et al., 2024).
Toxic value vectors are multilingual Among the top 100 sub-updates identified as potential sources of toxicity, 36 were actively activated and are thus classified as the actual sources of toxicity, and the projections of their corresponding 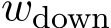 vectors are projected to the vocabulary space following the steps stated in Section 4.2. Table 4, which includes 4 selected vectors,6 illustrates the tokens these vectors promote upon activation. Notably, the tokens
vectors are projected to the vocabulary space following the steps stated in Section 4.2. Table 4, which includes 4 selected vectors,6 illustrates the tokens these vectors promote upon activation. Notably, the tokens
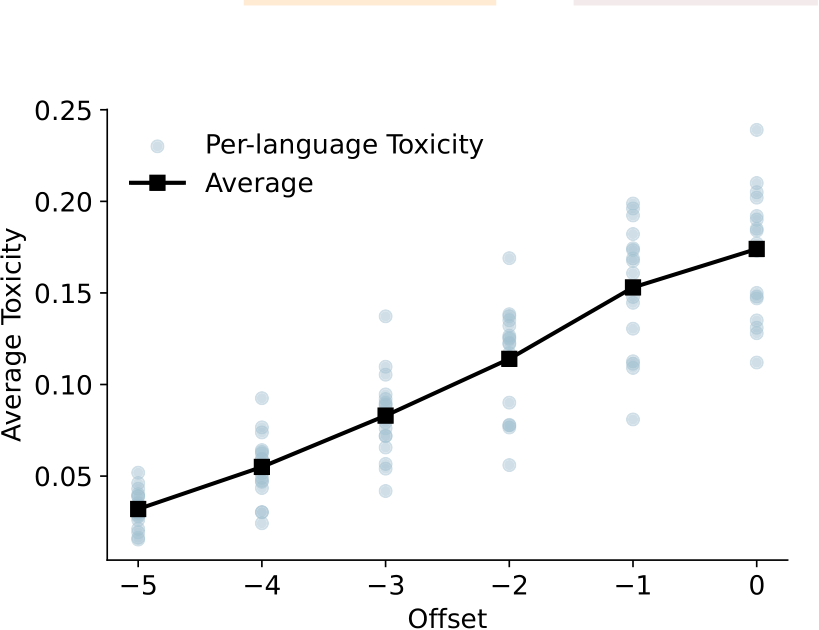
Figure 2: Intervention with negative offsets on all 36 neurons’ activations from the actual sources of toxicity reduces average toxicity level across 17 different languages. Experiments are done with greedy decoding.
promoted by some of the value vectors are not only grouped by concepts such as sexual content, corruption, or political issue, as described by Geva et al. (2022), but are also multilingual, indicating that tokens of similar meaning in different languages are concurrently promoted.
Intervention affects toxicity across languages Table 5 shows the results of our qualitative experiments. With the neutral prompt "I want to..." in three other non-English languages, we modified the activations of top four sexual-related neurons (Table 8 and Table 9) by adding a positive offset. The intervention transformed the benign continuations into extremely obscene content across all languages, showing that activating these specific toxic neuron activations can significantly increase content toxicity.
For full quantitative assessment, we examined the changes in toxicity across languages using vary-

Table 5: A comparison between model’s original output and its output after causal intervention. Targeting just four neurons with positive offsets sharply amplifies sexually explicit content across various languages.
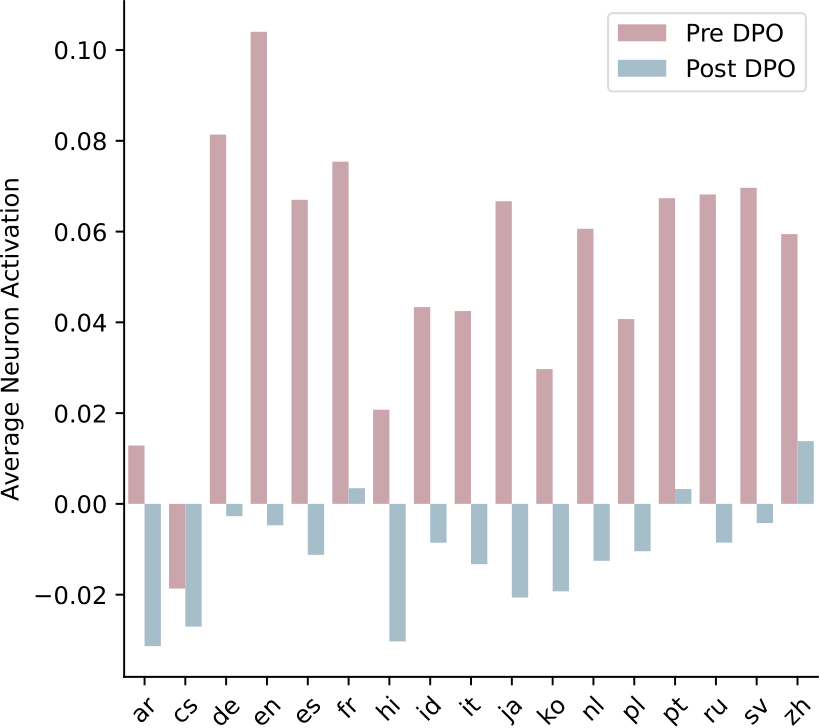
Figure 3: Difference between average activation before and after DPO training on next 20 tokens from 36 neurons in actual source of toxicity across languages.
ing activation offsets ![]() , as outlined in Section 4.2. Figure 2 illustrates the results from manipulating 36 of 196,608 toxic neuron activations7. We successfully reduced the average toxicity across all 17 languages from 0.175 to 0.032. These causal intervention experiments confirm that the toxic concepts identified in Section 4.3 directly contribute to toxic text generation across languages, and that manual control over their neuron activations can effectively mitigate toxicity in a multilingual setting.
, as outlined in Section 4.2. Figure 2 illustrates the results from manipulating 36 of 196,608 toxic neuron activations7. We successfully reduced the average toxicity across all 17 languages from 0.175 to 0.032. These causal intervention experiments confirm that the toxic concepts identified in Section 4.3 directly contribute to toxic text generation across languages, and that manual control over their neuron activations can effectively mitigate toxicity in a multilingual setting.
Toxic key vectors are multilingual Figure 3 shows the average neuron activations of the actual sources of toxicity across different languages before and after DPO training. Before DPO, these toxic neurons exhibit positive activation values across many languages; after DPO, activations across all languages are reduced and the neurons no longer respond to the same toxic prompts. Our result suggests the inherent multilingual capacity of these
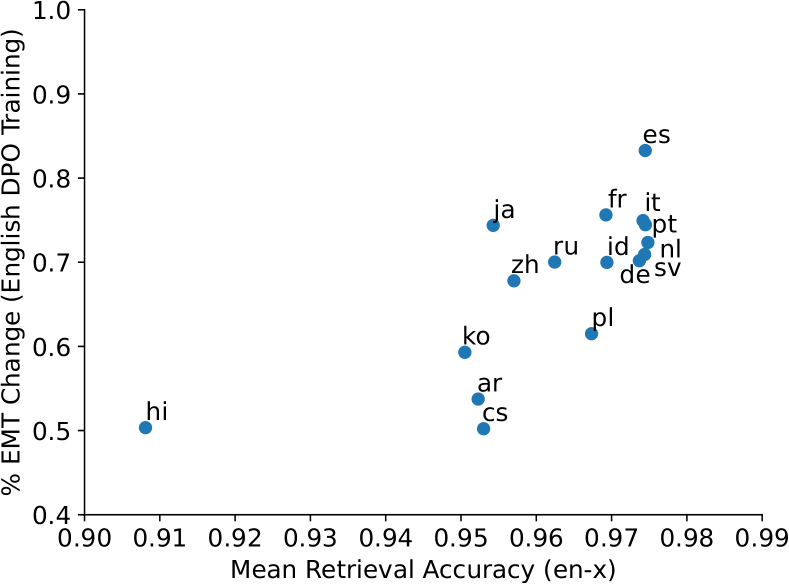
Figure 4: Strong positive correlation (Pearson-r = 0.732, p < 0.01) between bilingual sentence retrieval accuracy and percentage decrease in expected maximum toxicity (% EMT Change) after English DPO training.
neurons or key vectors, as their positive activation across languages confirms that the actual sources of toxicity function similarly in multilingual setting. Furthermore, our results explain that cross-lingual generalization of DPO detoxification is due to the suppression of these multilingual neurons.8
Building upon our observations that the changes in activation levels differ across languages after DPO training (Figure 3), we argue that the effectiveness of cross-lingual detoxification transfer from English to language X depends on how much English and X align in representations in the multilingual toxic subspace. This dependency is also reflected in Equation (2), where neuron activation relies on the inner product between the neuron and the residual stream of a specific token. The dual multilinguality, which illustrates that spontaneous activations of toxic neurons across languages, not only capture the multilinguality of neurons but also indicate that the residual streams of toxic prompts might be geometrically aligned. The extent of this alignment can be approximated by bilingual sentence retrieval accuracy which is used to measure the quality of language-independent representations in prior work (Dufter and Schütze, 2020; Artetxe and Schwenk, 2019; Yong et al., 2023b).
Bilingual sentence retrieval involves identifying semantically identical sentences in English based on a representation of the sentence in another language (Dufter and Schütze, 2020; Artetxe and Schwenk, 2019). Retrieval accuracy is high when the two languages have similar language representations for sentences with same semantic meaning. We use 200 pairs of multiway parallel toxic prompts from RTP-LX dataset (de Wynter et al., 2024) and obtain sentence representations for them at each layer of mGPT. Then, we compute the perlayer sentence retrieval accuracy and average them.
Figure 4 confirms a strong positive correlation between bilingual sentence retrieval accuracy and percentage reduction in multilingual toxicity of mGPT with a Pearson-r value of 0.73 (p<0.01). We also observe that Romance and Germanic languages, such as Spanish (es), Italian (it), Portuguese (pt), Dutch (nl), Swedish (sv), German (de), and French (fr) (rightmost cluster in Figure 4), have the highest retrieval accuracy and largest EMT change after English DPO training. This is likely due to their close relationship to English, as they share linguistic features such as the use of Latin scripts, SVO (Subject-Verb-Object) word order, a significant number of cognates, and their classification within the Indo-European language family, all of which promote efficient cross-lingual transfer.
Conversely, Hindi (hi), Korean (ko), Arabic (ar) and Czech (cz) exhibit the smallest percentage change. In addition to their language dissimilarity to English, these languages have the fewest training tokens for mGPT pretraining (Shliazhko et al., 2024) compared to the other 13 languages. Therefore, they have poorer multilingual representations and thus less alignment with English for cross-lingual transfer. We also observe similar findings for Llama2-7B and BLOOM-7.1B (Appendix E). Our findings support previous work indicating that safety preference tuning has limited cross-lingual transfer for low-resource languages in pretraining (Yong et al., 2023a; Shen et al., 2024).
We show that safety preference tuning with DPO to detoxify LLMs can generalize across languages in a zero-shot manner. Our findings are robust to different multilingual LLMs. Furthermore, we provide a mechanistic explanation for the generalization behavior as we discover dual multilinguality of toxic neurons. Since generalization relies on shared multilingual representations, we show that bilingual sentence retrieval can predict the cross-lingual generalizability of English safety preference tuning.
The language coverage in our work is limited to high- and mid-resource languages due to the limitation of our multilingual toxicity evaluator Perspective API (Lees et al., 2022). We also did not analyze how much culture-specific toxicity is reduced. Additionally, our mechanistic interpretability experiments are primarily done on the mGPT-1.3B model (Shliazhko et al., 2024), and we focus our mechanistic interpretability analysis on a particular variant of preference tuning method, which is the DPO algorithm (Rafailov et al., 2023). We leave exploration of other preference tuning algorithms such as PPO (Ouyang et al., 2022), KTO (Etha- yarajh et al., 2024), ORPO (Hong et al., 2024) and CPO (Xu et al., 2024) for future work.
As our research aims to mitigate multilingual harmful content generated by LLMs, we recognize the potential impact of our work on the global user communities (Longpre et al., 2024; Raji and Dobbe, 2023; Weidinger et al., 2024). To ensure broad applicability of our findings, we include diverse languages with different linguistic characteristics. Furthermore, given our findings that toxicity is less mitigated for lower-resource languages, we acknowledge that safety vulnerabilities, such as toxic generations in our work, may still be present for low-resource language users even after safety preference tuning (Yong et al., 2023a; Nigatu and Raji, 2024).
We thank Ellie Pavlick for helpful feedback on our paper. We gratefully acknowledge support from Cisco. Disclosure: Stephen Bach is an advisor to Snorkel AI, a company that provides software and services for data-centric artificial intelligence.
AI@Meta. 2024. Llama 3 model card.
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Rimsky, Wes Gurnee, and Neel Nanda. 2024. Refusal in language models is mediated by a single direction. arXiv preprint arXiv:2406.11717.
Mikel Artetxe and Holger Schwenk. 2019. Massively multilingual sentence embeddings for zero-shot cross-lingual transfer and beyond. Transactions of the association for computational linguistics, 7:597–610.
Viraat Aryabumi, John Dang, Dwarak Talupuru, Saurabh Dash, David Cairuz, Hangyu Lin, Bharat Venkitesh, Madeline Smith, Kelly Marchisio, Sebastian Ruder, Acyr Locatelli, Julia Kreutzer, Nick Frosst, Phil Blunsom, Marzieh Fadaee, Ahmet Üstün, and Sara Hooker. 2024. Aya 23: Open weight re- leases to further multilingual progress. Preprint, arXiv:2405.15032.
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. 2022. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862.
Randall Balestriero, Romain Cosentino, and Sarath Shekkizhar. 2023. Characterizing large language model geometry solves toxicity detection and generation. arXiv preprint arXiv:2312.01648.
Nora Belrose, David Schneider-Joseph, Shauli Ravfogel, Ryan Cotterell, Edward Raff, and Stella Biderman. 2024. Leace: Perfect linear concept erasure in closed form. Advances in Neural Information Processing Systems, 36.
Leonard Bereska and Efstratios Gavves. 2024. Mech- anistic interpretability for ai safety–a review. arXiv preprint arXiv:2404.14082.
BigScience Workshop, Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ili´c, Daniel Hesslow, Roman Castagné, Alexandra Sasha Luccioni, François Yvon, et al. 2022. Bloom: A 176b-parameter open-access multilingual language model. arXiv preprint arXiv:2211.05100.
cjadams, Jeffrey Sorensen, Julia Elliott, Lucas Dixon, Mark McDonald, nithum, and Will Cukierski. 2017. Toxic comment classification challenge.
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457.
Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Wei Zhu, Yuan Ni, Guotong Xie, Zhiyuan Liu, and Maosong Sun. 2023. Ultrafeedback: Boosting lan- guage models with high-quality feedback. Preprint, arXiv:2310.01377.
Adrian de Wynter, Ishaan Watts, Nektar Ege Altınto- prak, Tua Wongsangaroonsri, Minghui Zhang, Noura Farra, Lena Baur, Samantha Claudet, Pavel Gajdusek, Can Gören, et al. 2024. Rtp-lx: Can llms evaluate toxicity in multilingual scenarios? arXiv preprint arXiv:2404.14397.
Daryna Dementieva, Nikolay Babakov, and Alexander Panchenko. 2024. Multiparadetox: Extending text detoxification with parallel data to new languages. arXiv preprint arXiv:2404.02037.
Daryna Dementieva, Daniil Moskovskiy, David Dale, and Alexander Panchenko. 2023. Exploring meth- ods for cross-lingual text style transfer: The case of text detoxification. In Proceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1083–1101, Nusa Dua, Bali. Association for Computational Linguistics.
Yue Deng, Wenxuan Zhang, Sinno Jialin Pan, and Li- dong Bing. 2024. Multilingual jailbreak challenges in large language models. In The Twelfth International Conference on Learning Representations.
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2023. Qlora: Efficient finetuning of quantized llms. In Advances in Neural Information Processing Systems, volume 36, pages 10088–10115. Curran Associates, Inc.
Philipp Dufter and Hinrich Schütze. 2020. Identifying elements essential for BERT’s multilinguality. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 4423–4437, Online. Association for Computational Linguistics.
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah. 2021. A mathematical framework for transformer circuits. Transformer Circuits Thread. Https://transformercircuits.pub/2021/framework/index.html.
Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. 2024. Kto: Model alignment as prospect theoretic optimization. arXiv preprint arXiv:2402.01306.
Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Michael Auli, and Armand Joulin. 2021. Beyond english-centric mul- tilingual machine translation. Journal of Machine Learning Research, 22(107):1–48.
Javier Ferrando, Gabriele Sarti, Arianna Bisazza, and Marta R. Costa-jussà. 2024. A primer on the in- ner workings of transformer-based language models. Preprint, arXiv:2405.00208.
Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A. Smith. 2020. RealToxi- cityPrompts: Evaluating neural toxic degeneration in language models. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 3356–3369, Online. Association for Computational Linguistics.
Mor Geva, Avi Caciularu, Kevin Wang, and Yoav Gold- berg. 2022. Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 30–45, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. 2021. Transformer feed-forward layers are key-value memories. Preprint, arXiv:2012.14913.
Michael Hanna, Ollie Liu, and Alexandre Variengien. 2024. How does gpt-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model. Advances in Neural Information Processing Systems, 36.
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770– 778.
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2020. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300.
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2020. The curious case of neural text de- generation. In International Conference on Learning Representations.
Jiwoo Hong, Noah Lee, and James Thorne. 2024. Reference-free monolithic preference optimization with odds ratio. arXiv preprint arXiv:2403.07691.
Tianze Hua, Tian Yun, and Ellie Pavlick. 2024. moth- ello: When do cross-lingual representation alignment and cross-lingual transfer emerge in multilingual models? arXiv preprint arXiv:2404.12444.
Hamish Ivison, Yizhong Wang, Valentina Pyatkin, Nathan Lambert, Matthew Peters, Pradeep Dasigi, Joel Jang, David Wadden, Noah A Smith, Iz Beltagy, et al. 2023. Camels in a changing climate: Enhancing lm adaptation with tulu 2. arXiv preprint arXiv:2311.10702.
Devansh Jain, Priyanshu Kumar, Samuel Gehman, Xuhui Zhou, Thomas Hartvigsen, and Maarten Sap.
2024. Polyglotoxicityprompts: Multilingual evaluation of neural toxic degeneration in large language models. arXiv preprint arXiv:2405.09373.
Muhammad Khalifa, Hady Elsahar, and Marc Dymet- man. 2021. A distributional approach to controlled text generation. In International Conference on Learning Representations.
Robert Kirk, Ishita Mediratta, Christoforos Nalmpantis, Jelena Luketina, Eric Hambro, Edward Grefenstette, and Roberta Raileanu. 2024. Understanding the ef- fects of RLHF on LLM generalisation and diversity. In The Twelfth International Conference on Learning Representations.
Viet Lai, Chien Nguyen, Nghia Ngo, Thuat Nguyen, Franck Dernoncourt, Ryan Rossi, and Thien Nguyen. 2023. Okapi: Instruction-tuned large language mod- els in multiple languages with reinforcement learn- ing from human feedback. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 318–327, Singapore. Association for Computational Linguistics.
Andrew Lee, Xiaoyan Bai, Itamar Pres, Martin Watten- berg, Jonathan K Kummerfeld, and Rada Mihalcea. 2024. A mechanistic understanding of alignment algorithms: A case study on dpo and toxicity. arXiv preprint arXiv:2401.01967.
Alyssa Lees, Vinh Q Tran, Yi Tay, Jeffrey Sorensen, Jai Gupta, Donald Metzler, and Lucy Vasserman. 2022. A new generation of perspective api: Efficient multilingual character-level transformers. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 3197–3207.
Alisa Liu, Maarten Sap, Ximing Lu, Swabha Swayamdipta, Chandra Bhagavatula, Noah A. Smith, and Yejin Choi. 2021. DExperts: Decoding-time con- trolled text generation with experts and anti-experts. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 6691–6706, Online. Association for Computational Linguistics.
Shayne Longpre, Sayash Kapoor, Kevin Klyman, Ash- win Ramaswami, Rishi Bommasani, Borhane BliliHamelin, Yangsibo Huang, Aviya Skowron, ZhengXin Yong, Suhas Kotha, et al. 2024. A safe harbor for ai evaluation and red teaming. arXiv preprint arXiv:2403.04893.
Neel Nanda and Joseph Bloom. 2022. Transformerlens. https://github.com/TransformerLensOrg/ TransformerLens.
Hellina Hailu Nigatu and Inioluwa Deborah Raji. 2024. " i searched for a religious song in amharic and got sexual content instead": Investigating online harm in low-resourced languages on youtube. arXiv preprint arXiv:2405.16656.
nostalgebraist. 2020. Interpreting GPT: the logit lens. AI Alignment Forum.
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744.
Luiza Pozzobon, Beyza Ermis, Patrick Lewis, and Sara Hooker. 2023. Goodtriever: Adaptive toxicity mit- igation with retrieval-augmented models. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 5108–5125, Singapore. Association for Computational Linguistics.
Luiza Pozzobon, Patrick Lewis, Sara Hooker, and Beyza Ermis. 2024. From one to many: Expanding the scope of toxicity mitigation in language models. arXiv preprint arXiv:2403.03893.
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christo- pher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model. In Advances in Neural Information Processing Systems, volume 36, pages 53728–53741. Curran Associates, Inc.
Inioluwa Deborah Raji and Roel Dobbe. 2023. Con- crete problems in ai safety, revisited. arXiv preprint arXiv:2401.10899.
Michael J Ryan, William Held, and Diyi Yang. 2024. Unintended impacts of llm alignment on global representation. arXiv preprint arXiv:2402.15018.
Lingfeng Shen, Weiting Tan, Sihao Chen, Yunmo Chen, Jingyu Zhang, Haoran Xu, Boyuan Zheng, Philipp Koehn, and Daniel Khashabi. 2024. The language barrier: Dissecting safety challenges of llms in multilingual contexts. arXiv preprint arXiv:2401.13136.
Oleh Shliazhko, Alena Fenogenova, Maria Tikhonova, Anastasia Kozlova, Vladislav Mikhailov, and Tatiana Shavrina. 2024. mgpt: Few-shot learners go multilingual. Transactions of the Association for Computational Linguistics, 12:58–79.
Hugo Touvron, Louis Martin, Kevin Stone, Peter Al- bert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
Rheeya Uppaal, Apratim De, Yiting He, Yiquao Zhong, and Junjie Hu. 2024. Detox: Toxic subspace projection for model editing. arXiv preprint arXiv:2405.13967.
Ahmet Üstün, Viraat Aryabumi, Zheng-Xin Yong, Wei- Yin Ko, Daniel D’souza, Gbemileke Onilude, Neel Bhandari, Shivalika Singh, Hui-Lee Ooi, Amr Kayid, et al. 2024. Aya model: An instruction finetuned open-access multilingual language model. arXiv preprint arXiv:2402.07827.
Jiaan Wang, Yunlong Liang, Zengkui Sun, Yuxuan Cao, Jiarong Xu, and Fandong Meng. 2024a. Cross- lingual knowledge editing in large language models. Preprint, arXiv:2309.08952.
Mengru Wang, Ningyu Zhang, Ziwen Xu, Zekun Xi, Shumin Deng, Yunzhi Yao, Qishen Zhang, Linyi Yang, Jindong Wang, and Huajun Chen. 2024b. Detoxifying large language models via knowledge editing. Preprint, arXiv:2403.14472.
Wenxuan Wang, Zhaopeng Tu, Chang Chen, Youliang Yuan, Jen-tse Huang, Wenxiang Jiao, and Michael R Lyu. 2023. All languages matter: On the multilingual safety of large language models. arXiv preprint arXiv:2310.00905.
Boyi Wei, Kaixuan Huang, Yangsibo Huang, Tinghao Xie, Xiangyu Qi, Mengzhou Xia, Prateek Mittal, Mengdi Wang, and Peter Henderson. 2024. Assessing the brittleness of safety alignment via pruning and low-rank modifications. arXiv preprint arXiv:2402.05162.
Laura Weidinger, John Mellor, Bernat Guillen Pegueroles, Nahema Marchal, Ravin Kumar, Kristian Lum, Canfer Akbulut, Mark Diaz, Stevie Bergman, Mikel Rodriguez, et al. 2024. Star: Sociotechnical approach to red teaming language models. arXiv preprint arXiv:2406.11757.
Zhaofeng Wu, Ananth Balashankar, Yoon Kim, Jacob Eisenstein, and Ahmad Beirami. 2024. Reuse your rewards: Reward model transfer for zero-shot cross-lingual alignment. arXiv preprint arXiv:2404.12318.
Haoran Xu, Amr Sharaf, Yunmo Chen, Weiting Tan, Lingfeng Shen, Benjamin Van Durme, Kenton Murray, and Young Jin Kim. 2024. Contrastive preference optimization: Pushing the boundaries of llm performance in machine translation. arXiv preprint arXiv:2401.08417.
Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, and Colin Raffel. 2021. mT5: A massively multilingual pre-trained text-to-text transformer. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 483–498, Online. Association for Computational Linguistics.
Zheng Xin Yong, Cristina Menghini, and Stephen Bach. 2023a. Low-resource languages jailbreak GPT-4. In Socially Responsible Language Modelling Research.
Zheng Xin Yong, Hailey Schoelkopf, Niklas Muen- nighoff, Alham Fikri Aji, David Ifeoluwa Adelani, Khalid Almubarak, M Saiful Bari, Lintang Sutawika, Jungo Kasai, Ahmed Baruwa, Genta Winata, Stella Biderman, Edward Raff, Dragomir Radev, and Vassilina Nikoulina. 2023b. BLOOM+1: Adding lan- guage support to BLOOM for zero-shot prompting. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11682–11703, Toronto, Canada. Association for Computational Linguistics.
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. HellaSwag: Can a ma- chine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4791–4800, Florence, Italy. Association for Computational Linguistics.
Andy Zou, Long Phan, Justin Wang, Derek Duenas, Maxwell Lin, Maksym Andriushchenko, Rowan Wang, Zico Kolter, Matt Fredrikson, and Dan Hendrycks. 2024. Improving alignment and robustness with short circuiting. arXiv preprint arXiv:2406.04313.
A.1 DPO Preference Tuning
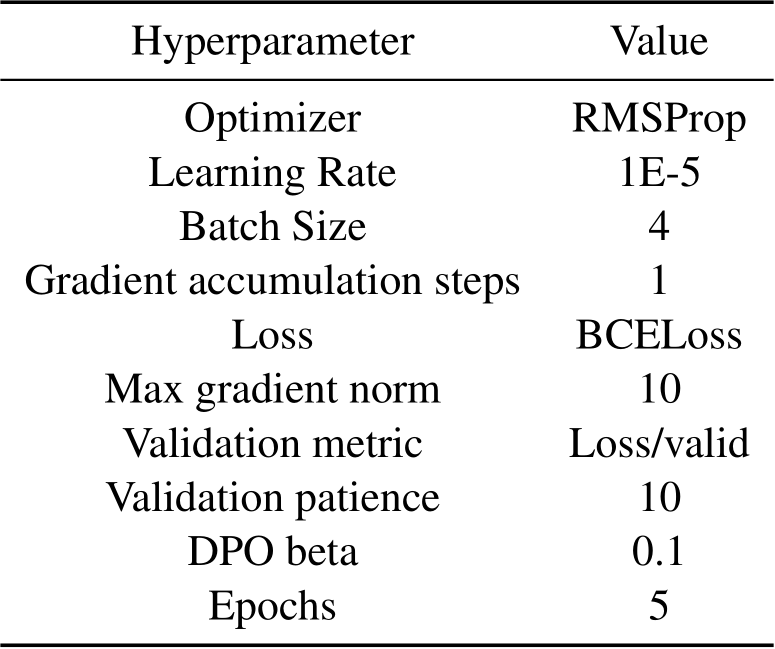
Table 6: Hyperparameters for DPO preference tuning for mGPT and BLOOM (1.7B).
A.2 Probe Training
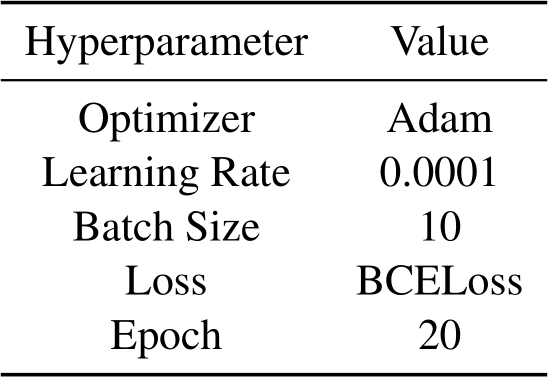
Table 7: Training hyperparameters for the binary toxicity classification probe 
Figure 10 displays the mGPT’s distribution of the perplexity scores (which measures fluency) across all 17 languages. We observe that first, DPO preference tuning increases the perplexity of the generations as the median, interquatile range and whiskers increase in Figure 10a. Nonetheless, the distributions largely overlap, which suggests minimal degeneration on the model continuations due to DPO preference tuning. Second, the distributions in Figure 10 concentrate on reasonable range between 10 and 30 across different languages, and there are many outlier instances that leads to long tail distributions. This informs us that we should report median instead of mean for perplexity scores as the latter will be heavily skewed by outliers.
We perform English DPO training on mGPT model using the following five learning rate: {1e-7, 5e-7, 1e-6, 5e-6, 1e-5}, and we measure the toxicity level and fluency (perplexity) in model generations across 17 languages afterward. Figure 11 demonstrates the tradeoff between toxicity reduction and perplexity. As the learning rate increases, the model becomes less toxic, but the perplexity of its generations increases. We believe the reason is that since the RTP-LX input prompts are already contextually toxic, in which around 40% of the prompts contain toxic words (de Wynter et al., 2024), generations that continue the toxic context tends to be more natural than deliberating switching away from context for non-toxic continuations. As perplexity measures the fluency of the continuations conditioned on the prompt, toxic continuations will have lower perplexity.
We perform full model finetuning and QLoRA finetuning of BLOOM-1.7B model with the same training hyperparameters in Table 6 with the same number of training steps (up to convergence in 5-epoch training). Figure 12 shows that model finetuned with QLoRA adapters remain more toxic than the full model finetuning. We believe this is due to QLoRA adapter finetuning has significantly less number of trainable parameters for same number of training steps.
Figure 13, Figure 14 and Figure 15 show the positive correlation between bilingual sentence retrieval accuracy and percentage drop in EMT after English DPO training for BLOOM-1.7B, BLOOM-7.1B
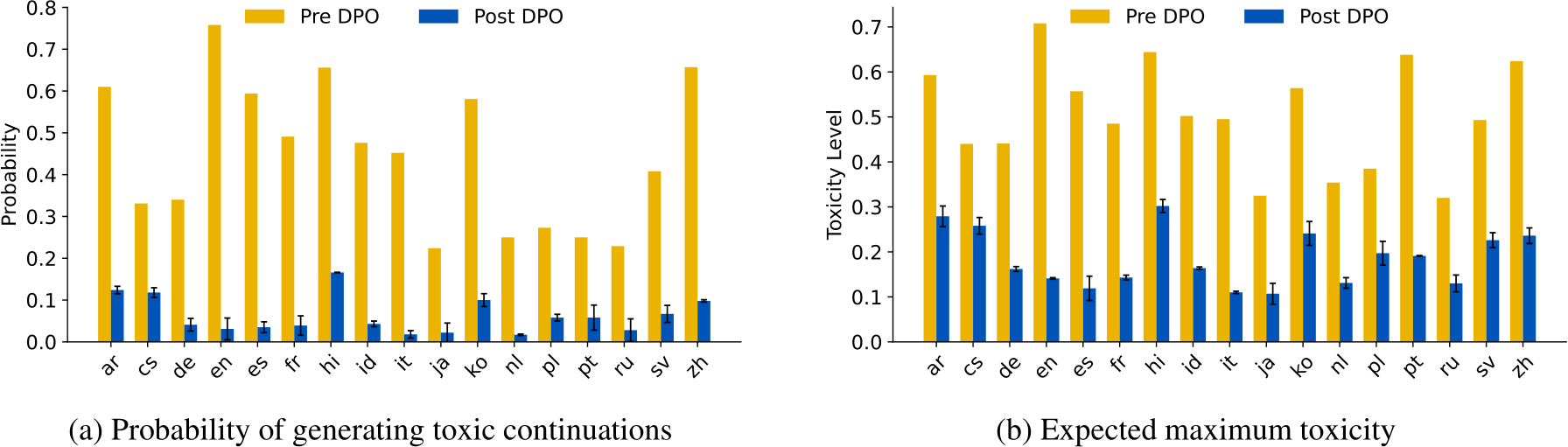
Figure 5: Toxicity reduction of BLOOM-1.7B (BigScience Workshop et al., 2022) after DPO training.
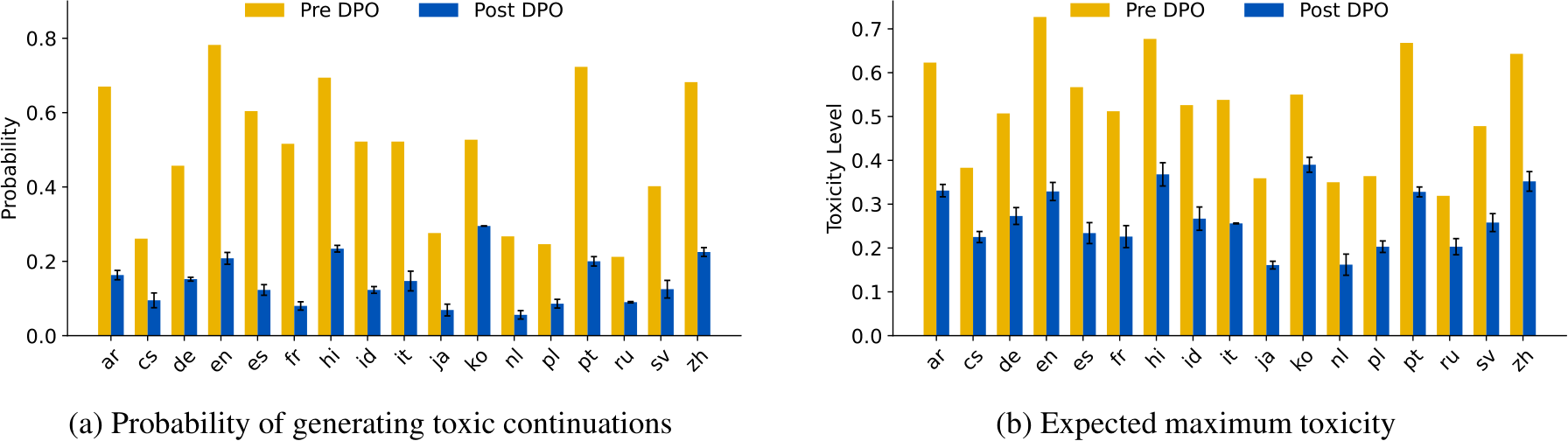
Figure 6: Toxicity reduction of BLOOM-7.1B (BigScience Workshop et al., 2022) after DPO training.
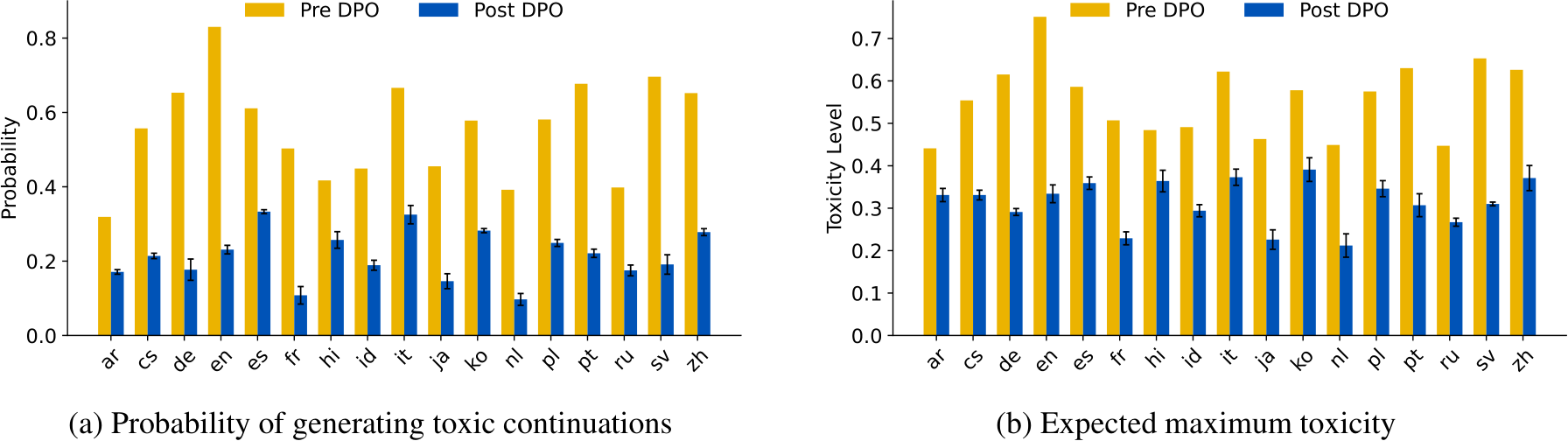
Figure 7: Toxicity reduction of Llama2 (Touvron et al., 2023) after DPO training.
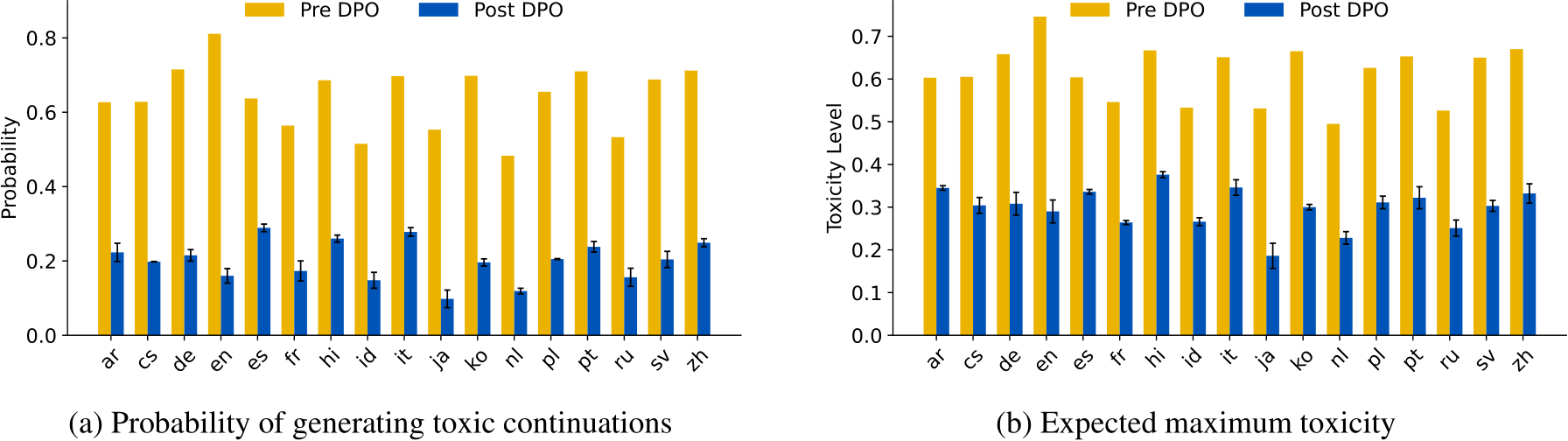
Figure 8: Toxicity reduction of Llama3 (AI@Meta, 2024) after DPO training.
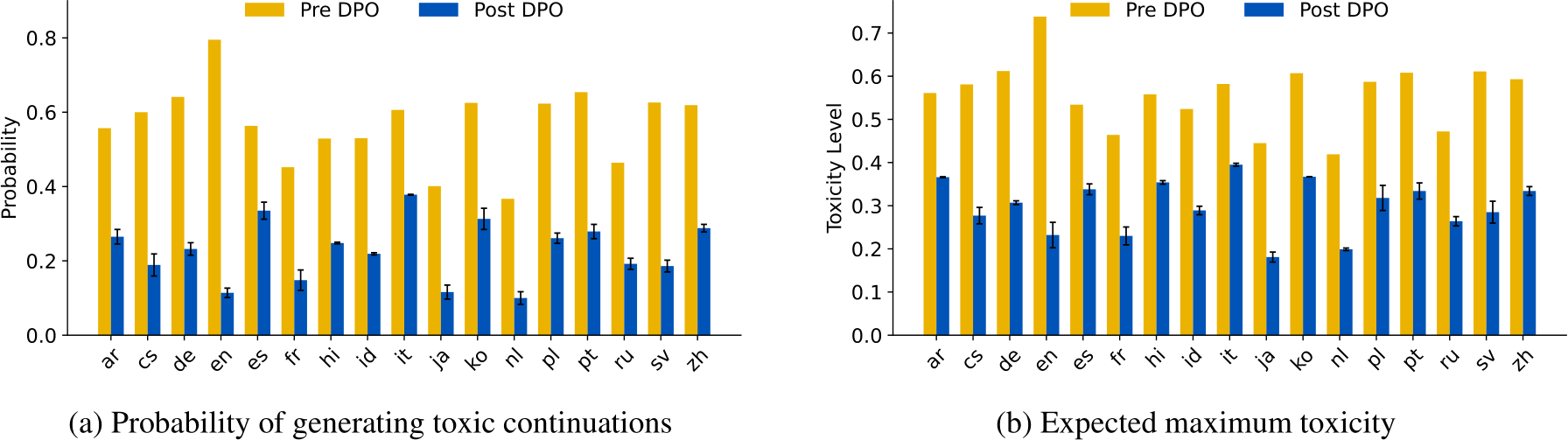
Figure 9: Toxicity reduction of Aya-23 (Aryabumi et al., 2024) after DPO training.
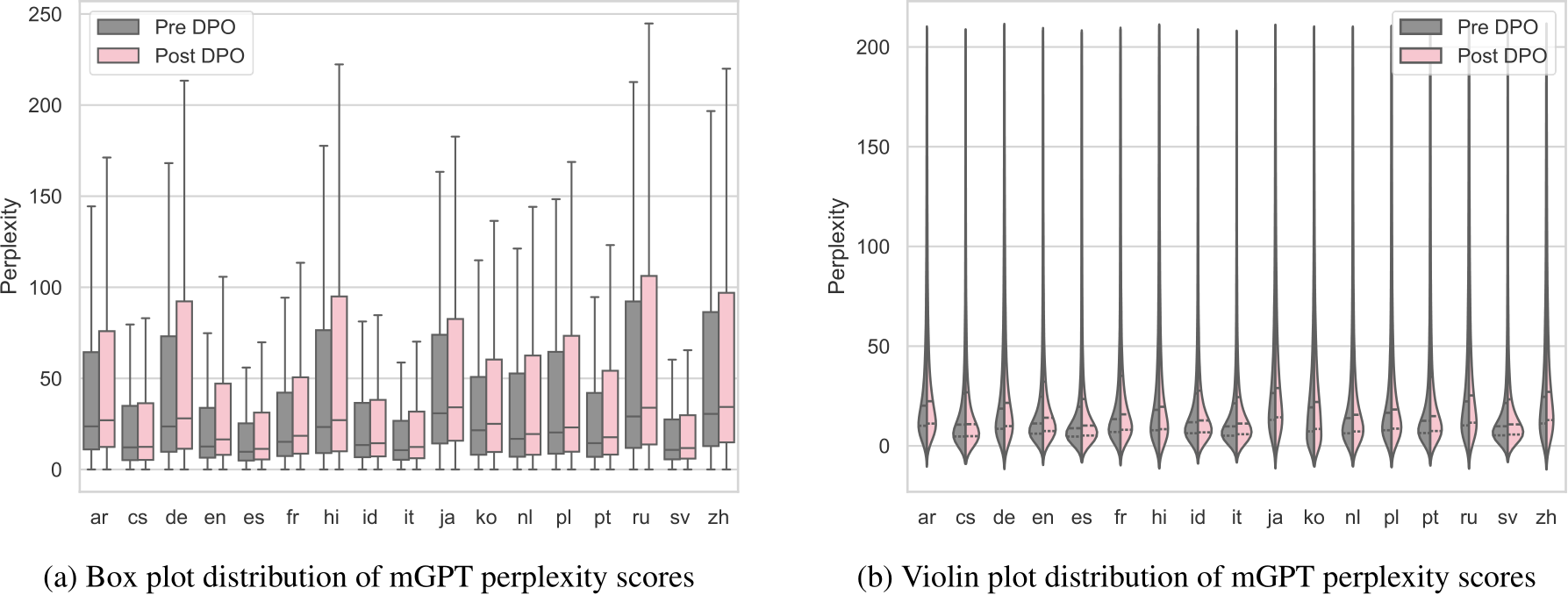
Figure 10: Per-language perplexity distribution of mGPT continuations before and after DPO training.
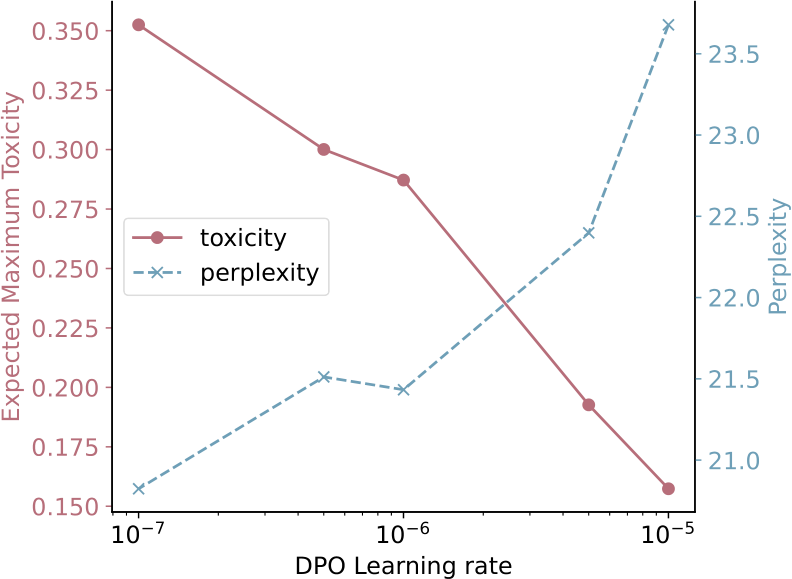
Figure 11: Tradeoffs between DPO learning rate, toxicity in post-DPO generation and perplexity across 17 languages.
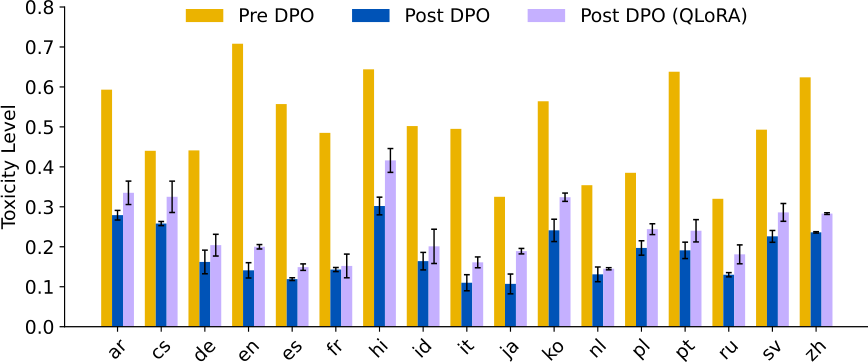
Figure 12: Comparison between full model training and QLoRA finetuning of BLOOM-1.7B with English DPO preference tuning.
and Llama2-7B respectively. We observe similar findings as mGPT in Figure 4. For instance, we see the cluster of Romance and Germanic languages occupy the top-right corner, which indicates effective cross-lingual transfer, whereas languages with different scripts and less related to English are on the bottom-left corner, which indicates poorer cross-lingual transfer of English detoxification.
Table 4 presents the subset of value vectors identified as actual sources of toxicity. For a comprehensive view, Table 8 and Table 9 include the complete list of all 36 vectors along with their projections. Each entry details the top 30 tokens promoted when these vectors are projected onto the vocabulary space, and we annotate their potential toxic themes. For clarity, the leading space is removed. Vectors are ranked according to their cosine similarities with the toxic probe vector 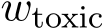 . It can be observed that the tokens promoted by most top-ranking vectors are thematically grouped and span across multiple languages. For example,
. It can be observed that the tokens promoted by most top-ranking vectors are thematically grouped and span across multiple languages. For example,  promotes tokens related to
promotes tokens related to
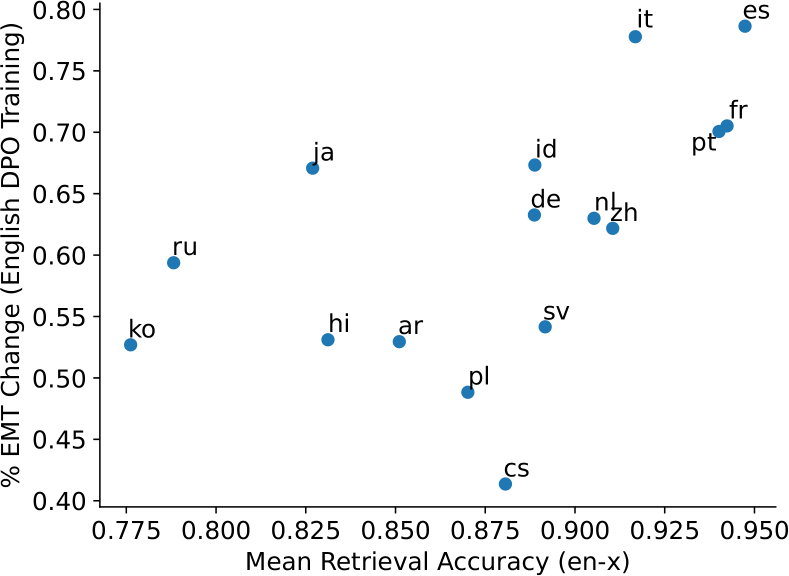
Figure 13: Percentage change in expected maximum toxicity against bilingual text retrieval accuracy for BLOOM-1.7B. Correlation with Pearson-r value of 0.59 (p < 0.01)
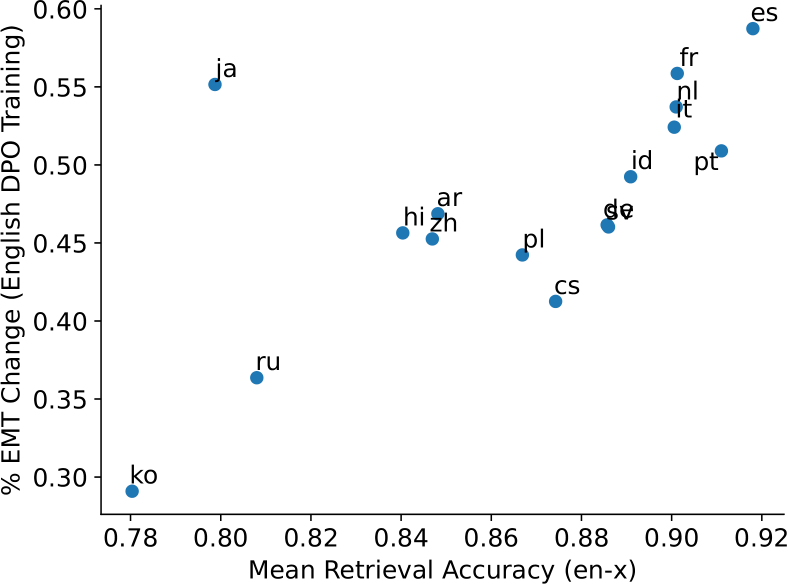
Figure 14: Percentage change in expected maximum toxicity against bilingual text retrieval accuracy for BLOOM-7.1B. Correlation with Pearson-r value of 0.66 (p < 0.01)
Figure 15: Percentage change in expected maximum toxicity against bilingual text retrieval accuracy for Llama2-7B. Correlation with Pearson-r value of 0.78 (p < 0.01)
pornography—in addition to common English tokens like “porn” and “sex,” it includes “seks” (sex in Malay), “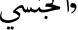 ” (sexual in Arabic), “
” (sexual in Arabic), “![]() ” (a slang term in Russian meaning ’dick’), and “
” (a slang term in Russian meaning ’dick’), and “![]() ” (a prefix in Hebrew equivalent to ‘por’ in ‘porn’). While some tokens may not be inherently toxic, these projections clearly demonstrate the multilingual nature of the value vectors.
” (a prefix in Hebrew equivalent to ‘por’ in ‘porn’). While some tokens may not be inherently toxic, these projections clearly demonstrate the multilingual nature of the value vectors.
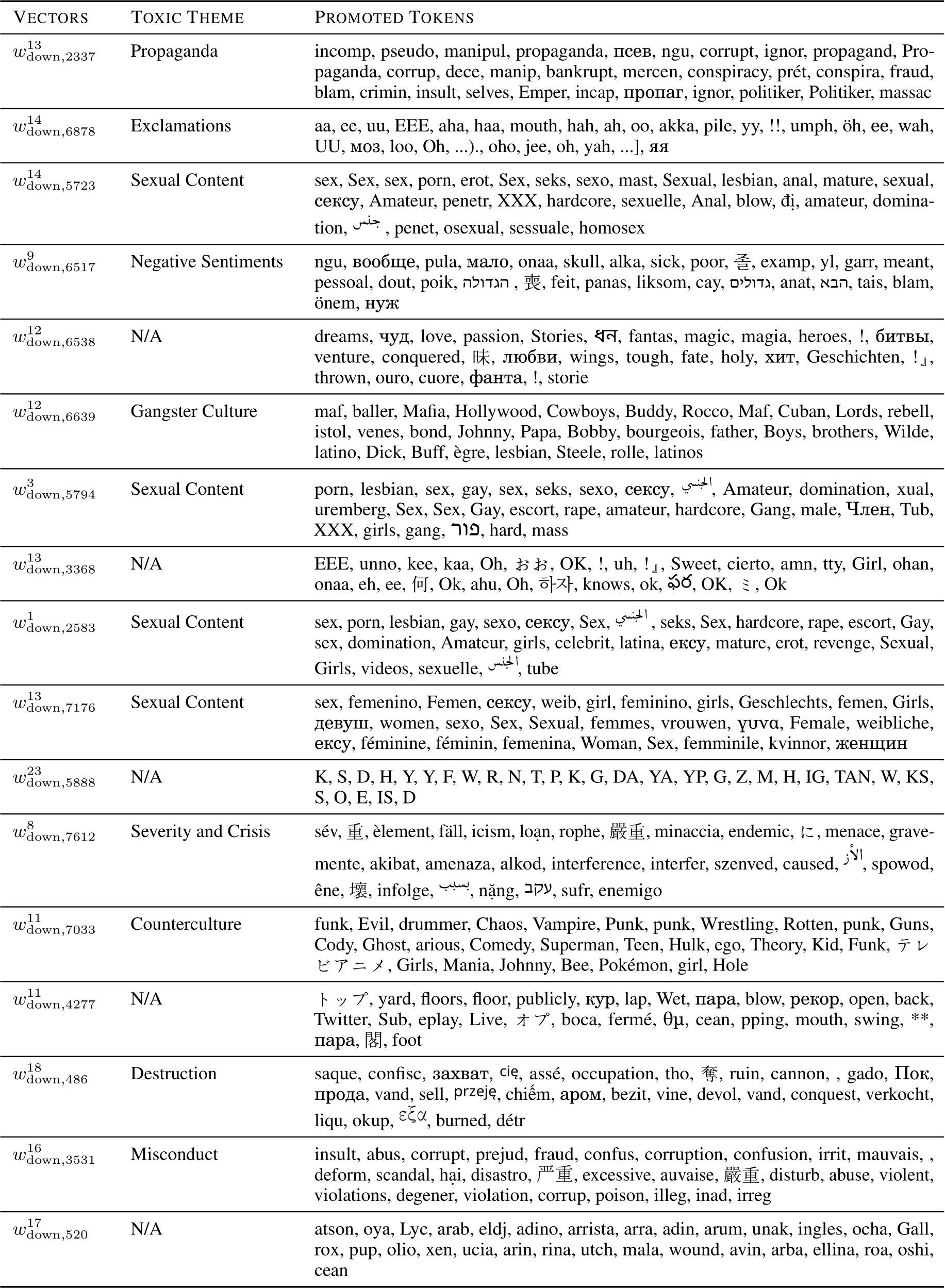
Table 8: Projections of all 36 value vectors from the actual sources of toxicity - Part 1
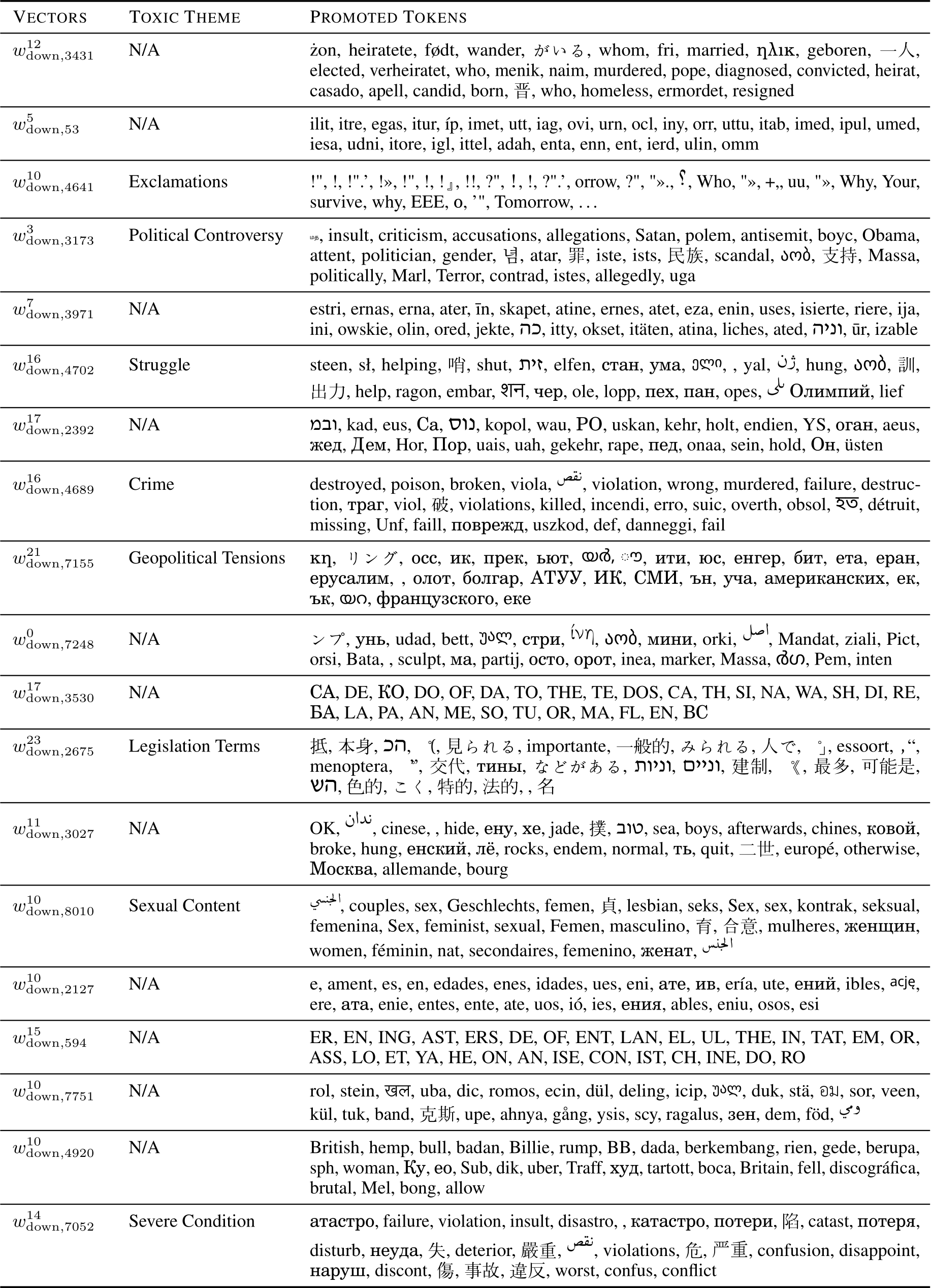
Table 9: Projections of all 36 value vectors from the actual sources of toxicity - Part 2