(e.g., general science, mathematics, physics, chemistry, materials science, biology, medicine, and geoscience), modalities (e.g., language, graph, vision, table, molecule, protein, genome, and climate time series), and sizes (from ![]() 100M to
100M to ![]() 100B parameters). For each field/modality, we investigate commonly adopted pre-training datasets, model architectures, and evaluation tasks of scientific LLMs. Following our motivation, when we discuss model architectures in detail, we link them back to Fig- ure 1 to build cross-field cross-modal connections. Moreover, we provide a structured summary of these scientific LLMs in Table A1-Table A6 (Ap- pendix A). Furthermore, for different fields, we introduce how LLMs have been deployed to benefit science by augmenting different aspects and stages of the scientific discovery process, such as hypothesis generation, theorem proving, experiment design, drug discovery, and weather forecasting.
100B parameters). For each field/modality, we investigate commonly adopted pre-training datasets, model architectures, and evaluation tasks of scientific LLMs. Following our motivation, when we discuss model architectures in detail, we link them back to Fig- ure 1 to build cross-field cross-modal connections. Moreover, we provide a structured summary of these scientific LLMs in Table A1-Table A6 (Ap- pendix A). Furthermore, for different fields, we introduce how LLMs have been deployed to benefit science by augmenting different aspects and stages of the scientific discovery process, such as hypothesis generation, theorem proving, experiment design, drug discovery, and weather forecasting.
2.1 Language
2.2 Language + Graph
ture in LLMs with Adapters (Singh et al., 2023), GNN-nested Transformers (Jin et al., 2023b), and Mixture-of-Experts Transformers (Zhang et al., 2023f) to better capture graph signals.
Graph-aware scientific LLMs are often evaluated on tasks regarding the relation between two text units (e.g., paper-paper or query-paper), including link prediction, retrieval, recommendation, and author name disambiguation. SciDocs (Cohan et al., 2020) and SciRepEval (Singh et al., 2023) are widely adopted benchmark datasets.
![]()
2.3 Applications in Scientific Discovery
Performant scientific LLMs can work alongside researchers throughout the entire scientific discovery process. Leaving field-specific applications for later sections, here we underscore LLMs’ general usefulness in brainstorming and evaluation: Lahav et al. (2022) integrate LLMs into a search engine for the discovery of scientific challenges and directions; Wang et al. (2023e), Yang et al. (2024d), Baek et al. (2024), Gu and Krenn (2024), and Si et al. (2024) leverage LLMs to generate novel scientific ideas, directions, and hypotheses on the basis of prior literature and existing knowledge; Zhang et al. (2023h) rely on LLMs to find expert reviewers for each submission; Liu and Shah (2023), Liang et al. (2024c), and D’Arcy et al. (2024) explore the capacity of GPT-4 to provide useful feedback on research papers to facilitate automatic review generation; Liang et al. (2024b,a) also observe the increasing use of LLMs in writing scientific papers and conference peer reviews.
![]()
![]()
3.1 Language
The pre-training text corpora for mathematics LLMs can be categorized into two classes: (1) multiple-choice QA, the representative datasets of which include MathQA (Amini et al., 2019), Ape210K (Zhao et al., 2020), and Math23K (Wang et al., 2017); as well as (2) generative QA, the representative datasets of which include GSM8K (Cobbe et al., 2021), MATH (Hendrycks et al., 2021b), and MetaMathQA (Yu et al., 2024c).
Similarly to general science LLMs, the backbone model of pioneering mathematics LLMs is BERT (TYPE 1.A, e.g., GenBERT (Geva et al., 2020) and MathBERT (Shen et al., 2021)), and these models are mostly trained via MLM. For GPT-based mathematics LLMs (TYPE 2.A, e.g., GSM8K-GPT (Cobbe et al., 2021) and NaturalProver (Welleck et al., 2022)), next token prediction and instruc-
the correct answer given the diagram and its caption, the question, and answer options. Renowned evaluation datasets include Geometry3K (Lu et al., 2021), GEOS (Seo et al., 2015), and MathVista (Lu et al., 2024).
![]()
3.3 Table
A large proportion of math knowledge is stored in the form of tabular data. For the “Table” modality, notable resources for pre-training include WikiTableQuestions (Pasupat and Liang, 2015), WikiSQL (Zhong et al., 2017), and WDC Web Table (Lehmberg et al., 2016).
The challenge in tables is similar to that in diagrams, namely to obtain linearized table representations. In most cases, tables are squeezed into linear text sequences as part of the context and are prepended with the question text as the model input. As one of the first works in this line of research, TAPAS (Herzig et al., 2020) (TYPE 1.A) adopts the MLM objective to predict the masked token in both textual and tabular contexts. Recent developments (Li et al., 2024b; Zhang et al., 2024f) resemble the design of TableLlama (Zhang et al., 2024e) (TYPE 2.B), with LLaMA-2 as the backbone and instruction tuning as the pre-training task.
Table LLMs are validated through table QA, where the model is asked to produce the correct answer given the table structure, data values, and a question text. Most existing studies have been evaluated on the WikiTableQuestions and WikiSQL datasets. TableInstruct (Zhang et al., 2024e) is the most recently developed comprehensive benchmark integrating 14 datasets across 11 tasks.
![]()
3.4 Applications in Scientific Discovery
Mathematics LLMs have great potential to assist humans in offering potential solutions. For instance, AlphaGeometry (Trinh et al., 2024) combines an LLM with a symbolic deduction engine, where the LLM generates useful constructs and the symbolic engine applies formal logic to find solutions. AlphaGeometry solves 25 out of 30 classical geometry problems adapted from the International Mathematical Olympiad. Sinha et al. (2024) extend AlphaGeometry by adding Wu’s method (Chou, 1988), further solving 27 out of 30, surpassing human gold medalists. FunSearch (Romera- Paredes et al., 2024) integrates LLM with program search. One notable achievement of FunSearch is its ability to find a new solution to the cap set problem in combinatorial optimization. The solutions generated can be faster and more efficient than those devised by human experts. In Li et al.
4.1 Language
4.2 Applications in Scientific Discovery
5.1 Language
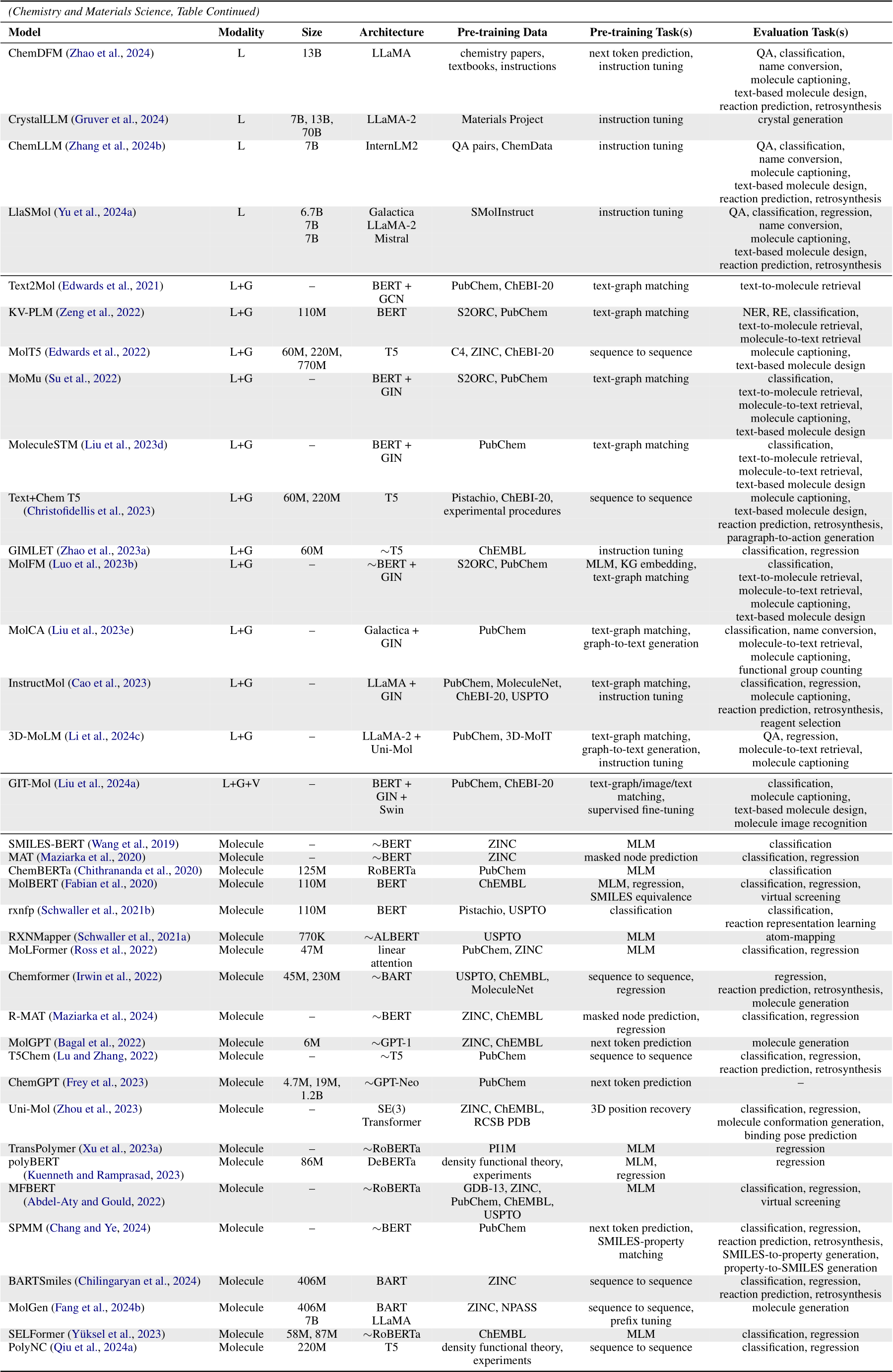
trained with MLM (TYPE 1.A, e.g., ChemBERT (Guo et al., 2022), MatSciBERT (Gupta et al., 2022), and BatteryBERT (Huang and Cole, 2022)). These models are usually evaluated on downstream tasks including reaction role labeling (Guo et al., 2022) and abstract classification (Gupta et al., 2022). Recently, researchers have focused more on large-scale decoder-only LLMs trained with next token prediction and instruction tuning (TYPE 2.A). Examples include ChemDFM (Zhao et al., 2024), ChemLLM (Zhang et al., 2024b), and LlaSMol (Yu et al., 2024a). Given the desired generalization capability of such models, they are evaluated on a diverse set of tasks such as name conversion (Kim et al., 2019), reaction prediction (Jin et al., 2017), retrosynthesis (Schneider et al., 2016), text-based molecule design (Edwards et al., 2022), and crystal generation (Antunes et al., 2023; Flam-Shepherd and Aspuru-Guzik, 2023; Gruver et al., 2024).
![]()
5.2 Language + Graph
Graphs are appropriate data structures for characterizing molecules (Jin et al., 2023a). Popular datasets containing molecular graphs include ChEBI-20 (Edwards et al., 2021, 2022), ZINC (Sterling and Irwin, 2015), and PCDes (Zeng et al., 2022).
In some scenarios, molecular graphs appear simultaneously with text information, thus existing works have explored how to encode both effectively. The first type of such models adopts a GNN as the graph encoder and an LLM as the text encoder. The two modalities are connected through contrastive learning (Liu et al., 2023d) (TYPE 3.C). For example, Text2Mol (Edwards et al., 2021) uses GCN (Kipf and Welling, 2017) and SciBERT to encode a molecule and its corresponding natural language description, respectively, for text-to-molecule retrieval. The second type of such models utilizes an LLM to encode text and graphs simultaneously (Zeng et al., 2022). Graphs can be either linearized to SMILES strings (Edwards et al., 2022) (TYPE 2.C) or projected onto virtual tokens with graph encoders (Zhao et al., 2023a; Liu et al., 2023e) (TYPE 2.D). For instance, 3D-MoLM (Li et al., 2024c) uses a 3-dimensional molecular encoder to represent molecules as tokens and feeds them together with instructions into LLaMA-2 for molecule-to-text retrieval and molecule captioning.
![]()
5.3 Language + Vision
Complementing text and graph modalities, molecular images form the vision modality in chemistry. Existing works adopt a similar philosophy to BLIP-2 (Li et al., 2023b), which represents each image
5.5 Applications in Scientific Discovery
plan, and perform chemical research. Moreover, LLMs accomplish complex tasks in chemistry, such as drug and catalyst design and molecular discovery, purely from instructions (White, 2023). For instance, Ramos et al. (2023) study catalyst and molecule design with in-context learning, removing the requirement for traditional training or simulation processes; ChatDrug (Liu et al., 2024b) explores drug editing using LLMs with a prompt module, a domain feedback module, and a conversation module; Jablonka et al. (2024) find that fine-tuned LLMs perform comparably to, or even better than, conventional techniques for many chemistry applications, spanning from the properties of molecules and materials to the yield of chemical reactions; DrugAssist (Ye et al., 2023a) serves as an LLMbased interactive model for molecule optimization through human-machine dialogue; Sprueill et al. (2023, 2024) use LLMs as agents to search for effective catalysts through Monte Carlo Tree Search and the feedback from an atomistic neural network model; Wang et al. (2024b) re-engineer crossover and mutation operations for molecular discovery using LLMs trained on extensive chemical datasets. Meanwhile, benchmarking studies by Mirza et al. (2024) demonstrate that although LLMs achieve superhuman proficiency in many chemical tasks, further research is critical to enhancing their safety and utility in chemical sciences.
![]()
6.1 Language
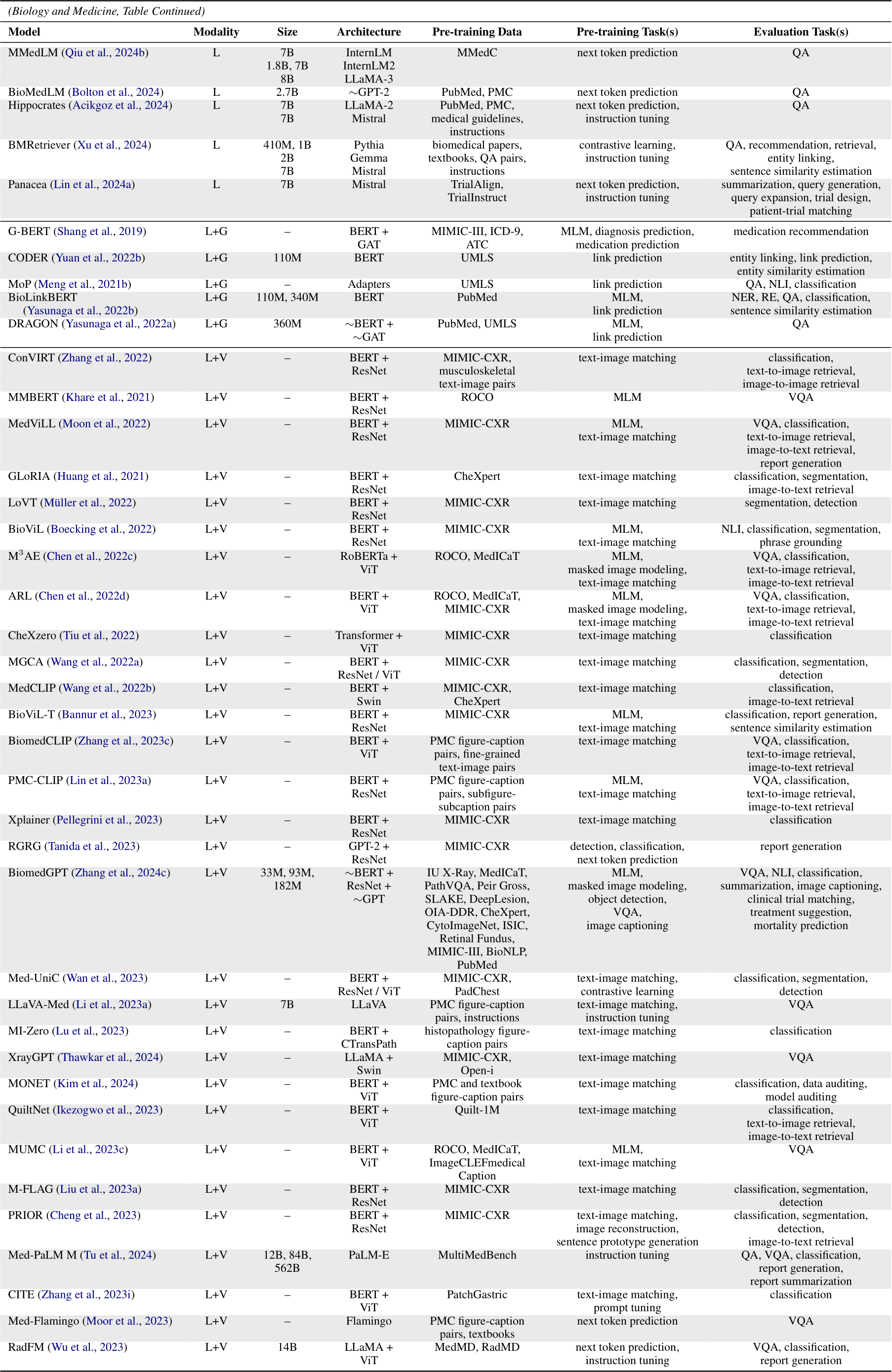
Besides research articles (e.g., titles/abstracts from PubMed (Lu, 2011) and full text from PMC (Beck and Sequeira, 2003)), pre-training corpora for biomedical LLMs include electronic health records (e.g., MIMIC-III (Johnson et al., 2016), MIMICIV (Johnson et al., 2023)), knowledge bases (e.g., UMLS (Bodenreider, 2004)), and health-related social media posts (e.g., COVID-19 tweets (Müller et al., 2023)). Recent studies further collect supervised fine-tuning and preference optimization datasets from medical exam questions, knowledge graphs, and doctor-patient dialogues. Examples include ChiMed (Ye et al., 2023b), MedInstruct-52k (Zhang et al., 2023d), and BiMed1.3M (Acikgoz et al., 2024), many of which have non-English components (e.g., Chinese and Arabic).
The watershed moment in the evolution biomedical LLMs is still the emergence of billion-parameter architectures and instruction tuning. Before that, a wide variety of moderate-sized back-
6.3 Language + Vision
Most biomedical vision-language models exploit
the CLIP architecture (Radford et al., 2021), where a text encoder and an image encoder are jointly trained to map the paired text and image closer via contrastive learning (TYPE 3.D). The choice of the text encoder evolves from BERT (Zhang et al., 2022) and GPT-2 (Huang et al., 2023) to LLaMA (Wu et al., 2023) and LLaMA-2 (Liu et al., 2023b), while the image encoder evolves from ResNet (Huang et al., 2021) to ViT (Zhang et al., 2023c) and Swin Transformer (Thawkar et al., 2024). MLM, masked image modeling, and text-text/image-image contrastive learning (i.e., by creating augmented views within the language/vision modality) are sometimes adopted as auxiliary pre-training tasks. Besides CLIP, other general-domain vision-language architectures, such as LLaVA (Li et al., 2023a), PaLM-E (Tu et al., 2024), and Gemini (Saab et al., 2024), have been explored. For instance, LLaVA-Med (TYPE 2.D) encodes images onto several visual tokens and prepends them to text tokens as the LLM input. Evaluation tasks of these models encompass image classification, segmentation, object detection, vision QA, text-to-image/image-to-text retrieval, and report generation, the benchmarks of which include CheXpert (Irvin et al., 2019), PadChest (Bustos et al., 2020), SLAKE (Liu et al., 2021a), etc.
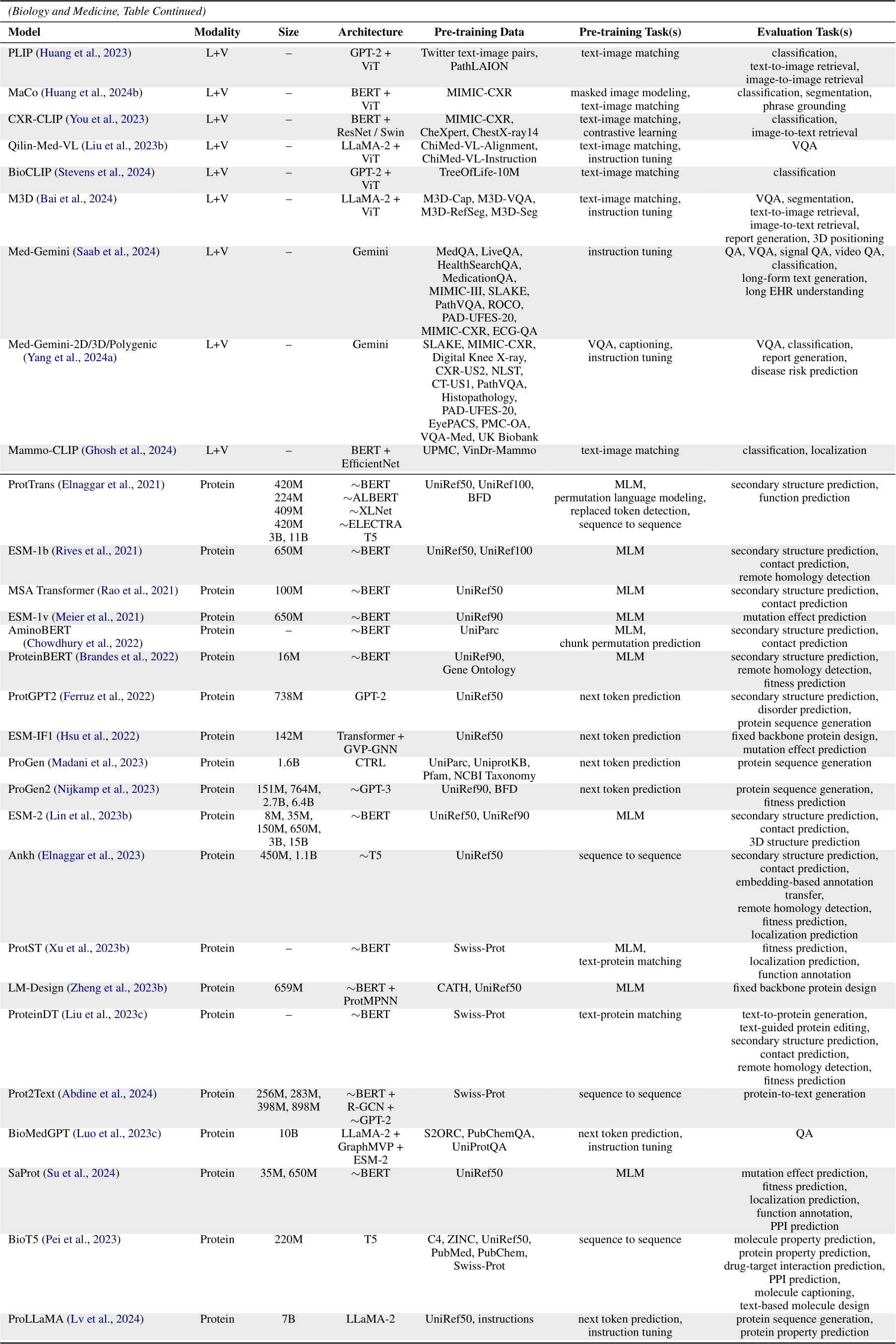
6.4 Protein, DNA, RNA, and Multiomics
The FASTA format (Lipman and Pearson, 1985) naturally represents proteins as amino acid sequences and DNAs/RNAs as nucleotide sequences, enabling models to treat them as “languages”. Representative resources of such sequences include UniRef (Suzek et al., 2015) and SwissProt (Bairoch and Apweiler, 2000) for proteins, GRCh38 (Harrow et al., 2012) and the 1000 Genomes Project (Consortium, 2015) for DNAs, as well as RNAcentral (Consortium, 2019) for RNAs.
Encoder-only protein, DNA, and RNA LLMs (TYPE 1.D), such as ESM-2 (Lin et al., 2023b), DNABERT (Ji et al., 2021), and RNABERT (Akiyama and Sakakibara, 2022), adopt BERT-like architectures and MLM as the pre-training task (i.e., predicting masked amino acids, nucleotides, k-mers, or codons); decoder-only models, such as ProGen (Madani et al., 2023) and DNAGPT (Zhang et al., 2023a), exploit GPT-like architectures and next token prediction as the pre-training task. There are also studies jointly considering text and protein modalities. For instance, ProtST (Xu et al., 2023b) matches protein sequences with their text descriptions (i.e., names and functions) via contrastive learning (TYPE 3.B); BioMedGPT
7.1 Language
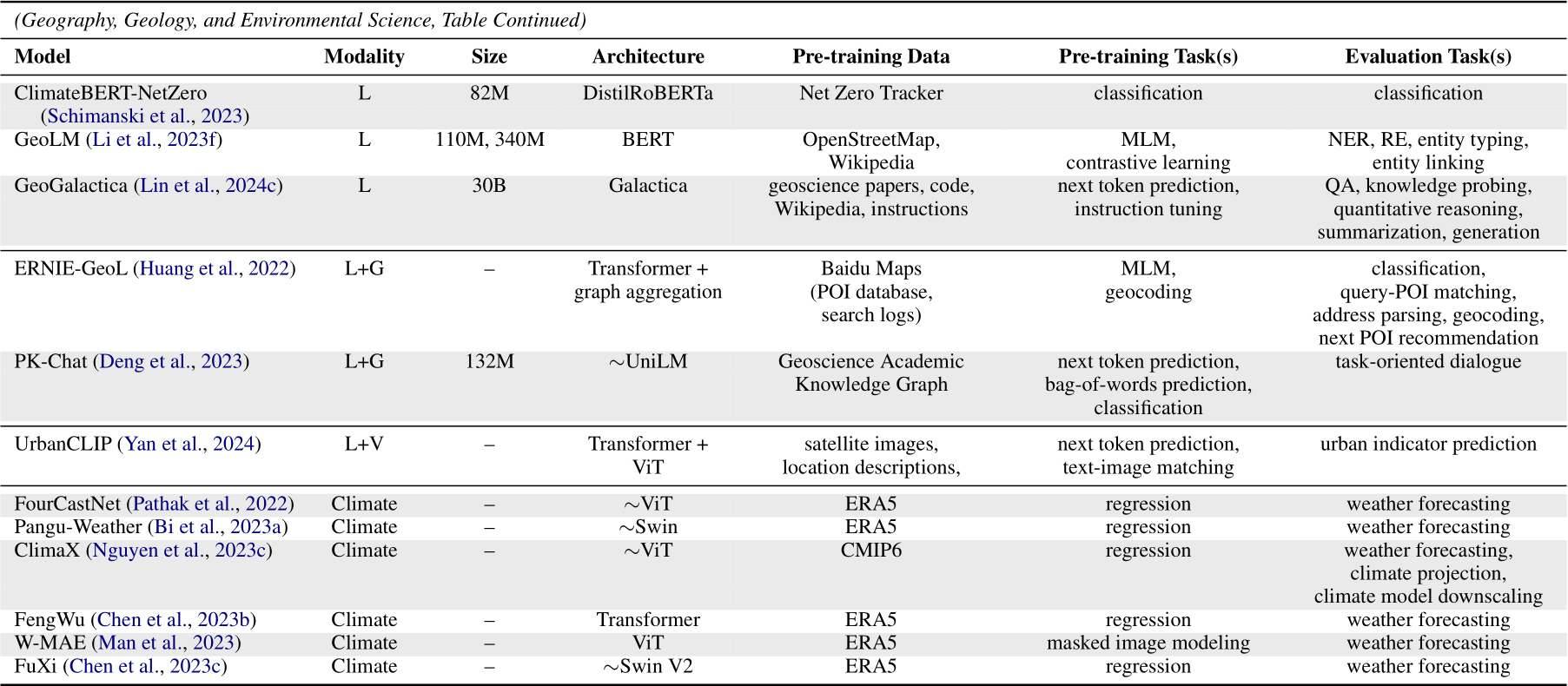
on a sequence of geolocations for geographic entity linking and query-POI matching, respectively. More recently, related studies concentrate on scaling up decoding-style autoregressive LLMs in geoscience (TYPE 2.A, e.g., K2 (Deng et al., 2024), OceanGPT (Bi et al., 2023b), and GeoGalactica (Lin et al., 2024c)). For instance, K2 and OceanGPT adapt LLaMA to geoscience and ocean science, respectively, via supervised fine-tuning with domain-specific instructions curated by human experts and/or augmented by general-domain LLMs. Evaluations of such models are conducted on geoscience benchmarks, such as GeoBench (Deng et al., 2024) and OceanBench (Bi et al., 2023b), which encompass a broad range of tasks including QA, classification, knowledge probing, reasoning, summarization, and generation.
![]()
7.2 Language + Graph
Some geoscience applications involve graph signals, such as heterogeneous POI networks and knowledge graphs. To handle such signals and text jointly, ERNIE-GeoL (Huang et al., 2022) introduces a Transformer-based aggregation layer to deeply fuse text and POI information within a BERT-based architecture; PK-Chat (Deng et al., 2023) combines an LLM with a pointer generation network on a knowledge graph to build a knowledge-driven dialogue system.
7.3 Language + Vision
Aerial views, together with location descriptions, profile urban regions. To address language and vision modalities jointly, UrbanCLIP (Yan et al., 2024) considers the CLIP architecture (TYPE 3.D), which is also widely adopted by biomedical vision-language models as mentioned in subsection 6.3, to perform text-image contrastive learning for urban indicator prediction.
![]()
7.4 Climate Time Series
The intuitions and methodologies used in LLMs also facilitate the construction of climate foundation models. Based on the ERA5 (Hersbach et al., 2020) and CMIP6 (Eyring et al., 2016) datasets of climate time series, previous studies exploit the ViT and Swin Transformer architectures to pre-train foundation models for weather forecasting. Representative models include FourCastNet (Pathak et al., 2022), Pangu-Weather (Bi et al., 2023a), etc.
![]()
7.5 Applications in Scientific Discovery
In geography, Wang et al. (2023b) and Zhou et al. (2024b) highlight the potential of LLMs in urban
and biomedicine. To mitigate this issue, retrieval-augmented generation (RAG) provides LLMs with relevant, up-to-date, and trustworthy information. However, previous RAG studies in the scientific domain mainly focus on retrieving text (Xiong et al., 2024) and knowledge (Jin et al., 2024), while scientific data are heterogeneous and multi-modal. We envision that cross-modal RAG (e.g., guiding text generation with relevant chemicals and proteins) will present additional opportunities to further enhance the trustworthiness of scientific LLMs.
![]()
This survey primarily covers LLMs in mathematics and natural sciences. We are aware that LLMs can also significantly impact social sciences by achieving remarkable performance in representative tasks (Ziems et al., 2024) and serving as agents for social simulation experiments (Horton, 2023), but we leave the survey of these efforts as future work due to space limitations. In addition, this paper focuses on LLMs pre-trained on scientific data or augmented with domain-specific knowledge to benefit scientific discovery. There are studies (Guo et al., 2023; Wang et al., 2024f; Yue et al., 2024a; Liang et al., 2024d) proposing new benchmark datasets of scientific problems but evaluating the performance of general-purpose LLMs only, and we do not include these works in our survey. Furthermore, some LLMs may belong to more than one field or modality category given our classification criteria in the paper. For instance, BioMedGPT (Luo et al., 2023c) is pre-trained on biology and chemistry data jointly; GIT-Mol (Liu et al., 2024a) considers the language, graph, and vision modalities simultaneously. For the sake of brevity, we introduce each of them in only one subsection.
![]()
![]()
Research was supported in part by US DARPA INCAS Program No. HR0011-21-C0165 and BRIES Program No. HR0011-24-3-0325, National Science Foundation IIS-19-56151, the Molecule Maker Lab Institute: An AI Research Institutes program supported by NSF under Award No. 2019897, and the Institute for Geospatial Understanding through an Integrative Discovery Environment (IGUIDE) by NSF under Award No. 2118329. Any opinions, findings, and conclusions or recommendations expressed herein are those of the authors and do not necessarily represent the views, either expressed or implied, of DARPA or the U.S. Government.
Jia Deng, Stella Biderman, and Sean Welleck. 2024. Llemma: An open language model for mathematics. In ICLR’24.
Jinheon Baek, Sujay Kumar Jauhar, Silviu Cucerzan, and Sung Ju Hwang. 2024. Researchagent: Iterative research idea generation over scientific literature with large language models. arXiv preprint arXiv:2404.07738.
![]()
Viraj Bagal, Rishal Aggarwal, PK Vinod, and U Deva Priyakumar. 2022. Molgpt: molecular generation using a transformer-decoder model. Journal of Chemical Information and Modeling, 62(9):2064–2076.
![]()
Fan Bai, Yuxin Du, Tiejun Huang, Max Q-H Meng, and Bo Zhao. 2024. M3d: Advancing 3d medical image analysis with multi-modal large language models. arXiv preprint arXiv:2404.00578.

Shruthi Bannur, Stephanie Hyland, Qianchu Liu, Fer- nando Perez-Garcia, Maximilian Ilse, Daniel C Castro, Benedikt Boecking, Harshita Sharma, Kenza Bouzid, Anja Thieme, et al. 2023. Learning to exploit temporal structure for biomedical vision-language processing. In CVPR’23, pages 15016– 15027.
![]()
Zhijie Bao, Wei Chen, Shengze Xiao, Kuang Ren, Jiaao Wu, Cheng Zhong, Jiajie Peng, Xuanjing Huang, and Zhongyu Wei. 2023. Disc-medllm: Bridging general large language models and real-world medical consultation. arXiv preprint arXiv:2308.14346.
![]()
Marco Basaldella, Fangyu Liu, Ehsan Shareghi, and Nigel Collier. 2020. Cometa: A corpus for medical entity linking in the social media. In EMNLP’20, pages 3122–3137.
![]()
Jeff Beck and Ed Sequeira. 2003. Pubmed central (pmc): An archive for literature from life sciences journals. The NCBI Handbook.
![]()
Iz Beltagy, Kyle Lo, and Arman Cohan. 2019. Scibert: A pretrained language model for scientific text. In EMNLP’19, pages 3615–3620.
![]()
Kaifeng Bi, Lingxi Xie, Hengheng Zhang, Xin Chen, Xiaotao Gu, and Qi Tian. 2023a. Accurate medium-range global weather forecasting with 3d neural networks. Nature, 619(7970):533–538.
![]()
Zhen Bi, Ningyu Zhang, Yida Xue, Yixin Ou, Dax- iong Ji, Guozhou Zheng, and Huajun Chen. 2023b. Oceangpt: A large language model for ocean science tasks. In ACL’24, pages 3357–3372.
![]()
Olivier Bodenreider. 2004. The unified medical lan- guage system (umls): integrating biomedical terminology. Nucleic Acids Research, 32(suppl_1):D267– D270.
He Cao, Zijing Liu, Xingyu Lu, Yuan Yao, and Yu Li. 2023. Instructmol: Multi-modal integration for building a versatile and reliable molecular assistant in drug discovery. arXiv preprint arXiv:2311.16208.
![]()
Souradip Chakraborty, Ekaba Bisong, Shweta Bhatt, Thomas Wagner, Riley Elliott, and Francesco Mosconi. 2020. Biomedbert: A pre-trained biomedical language model for qa and ir. In COLING’20, pages 669–679.
![]()
Jinho Chang and Jong Chul Ye. 2024. Bidirectional gen- eration of structure and properties through a single molecular foundation model. Nature Communications, 15(1):2323.
![]()
Jiaqi Chen, Tong Li, Jinghui Qin, Pan Lu, Liang Lin, Chongyu Chen, and Xiaodan Liang. 2022a. Unigeo: Unifying geometry logical reasoning via reformulating mathematical expression. In EMNLP’22, pages 3313–3323.
![]()
Jiaqi Chen, Jianheng Tang, Jinghui Qin, Xiaodan Liang, Lingbo Liu, Eric Xing, and Liang Lin. 2021. Geoqa: A geometric question answering benchmark towards multimodal numerical reasoning. In Findings of ACL’21, pages 513–523.
![]()
Jiayang Chen, Zhihang Hu, Siqi Sun, Qingxiong Tan, Yixuan Wang, Qinze Yu, Licheng Zong, Liang Hong, Jin Xiao, Tao Shen, et al. 2022b. Interpretable rna foundation model from unannotated data for highly accurate rna structure and function predictions. arXiv preprint arXiv:2204.00300.
Junying Chen, Xidong Wang, Anningzhe Gao, Feng Jiang, Shunian Chen, Hongbo Zhang, Dingjie Song, Wenya Xie, Chuyi Kong, Jianquan Li, et al. 2023a. Huatuogpt-ii, one-stage training for medical adaption of llms. arXiv preprint arXiv:2311.09774.
![]()
Kang Chen, Tao Han, Junchao Gong, Lei Bai, Fenghua Ling, Jing-Jia Luo, Xi Chen, Leiming Ma, Tianning Zhang, Rui Su, et al. 2023b. Fengwu: Pushing the skillful global medium-range weather forecast beyond 10 days lead. arXiv preprint arXiv:2304.02948.
![]()
Ken Chen, Yue Zhou, Maolin Ding, Yu Wang, Zhixiang Ren, and Yuedong Yang. 2024. Self-supervised learning on millions of primary rna sequences from 72 vertebrates improves sequence-based rna splicing prediction. Briefings in Bioinformatics, 25(3):bbae163.
![]()
Lei Chen, Xiaohui Zhong, Feng Zhang, Yuan Cheng, Yinghui Xu, Yuan Qi, and Hao Li. 2023c. Fuxi: a cascade machine learning forecasting system for 15-day global weather forecast. npj Climate and Atmospheric Science, 6(1):190.
Yirong Chen, Zhenyu Wang, Xiaofen Xing, Zhipei Xu, Kai Fang, Junhong Wang, Sihang Li, Jieling Wu, Qi Liu, Xiangmin Xu, et al. 2023d. Bianque: Balancing the questioning and suggestion ability of health llms with multi-turn health conversations polished by chatgpt. arXiv preprint arXiv:2310.15896.
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168.
![]()
Arman Cohan, Waleed Ammar, Madeleine van Zuylen, and Field Cady. 2019. Structural scaffolds for citation intent classification in scientific publications. In NAACL’19, pages 3586–3596.
Arman Cohan, Sergey Feldman, Iz Beltagy, Doug Downey, and Daniel S Weld. 2020. Specter: Document-level representation learning using citation-informed transformers. In ACL’20, pages 2270–2282.
The 1000 Genomes Project Consortium. 2015. A global reference for human genetic variation. Nature, 526(7571):68–74.
![]()
The RNAcentral Consortium. 2019. Rnacentral: a hub of information for non-coding rna sequences. Nucleic Acids Research, 47(D1):D221–D229.
Haotian Cui, Chloe Wang, Hassaan Maan, Kuan Pang, Fengning Luo, Nan Duan, and Bo Wang. 2024. scgpt: toward building a foundation model for single-cell multi-omics using generative ai. Nature Methods, 21(8):1470–1480.
Hugo Dalla-Torre, Liam Gonzalez, Javier Mendoza- Revilla, Nicolas Lopez Carranza, Adam Henryk Grzywaczewski, Francesco Oteri, Christian Dallago, Evan Trop, Bernardo P de Almeida, Hassan Sirelkhatim, et al. 2023. The nucleotide transformer: Building and evaluating robust foundation models for human genomics. bioRxiv, pages 2023–01.
Mike D’Arcy, Tom Hope, Larry Birnbaum, and Doug Downey. 2024. Marg: Multi-agent review generation for scientific papers. arXiv preprint arXiv:2401.04259.
![]()
Cheng Deng, Yuting Jia, Hui Xu, Chong Zhang, Jingyao Tang, Luoyi Fu, Weinan Zhang, Haisong Zhang, Xinbing Wang, and Chenghu Zhou. 2021. Gakg: A multimodal geoscience academic knowledge graph. In CIKM’21, pages 4445–4454.
Cheng Deng, Bo Tong, Luoyi Fu, Jiaxin Ding, Dexing Cao, Xinbing Wang, and Chenghu Zhou. 2023. Pk-chat: Pointer network guided knowledge driven generative dialogue model. arXiv preprint arXiv:2304.00592.
Cheng Deng, Tianhang Zhang, Zhongmou He, Qiyuan Chen, Yuanyuan Shi, Yi Xu, Luoyi Fu, Weinan Zhang, Xinbing Wang, Chenghu Zhou, et al. 2024. K2: A foundation language model for geoscience knowledge understanding and utilization. In WSDM’24, pages 161–170.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In NAACL’19, pages 4171–4186.
Veniamin Fishman, Yuri Kuratov, Maxim Petrov, Alek- sei Shmelev, Denis Shepelin, Nikolay Chekanov, Olga Kardymon, and Mikhail Burtsev. 2023. Genalm: A family of open-source foundational dna language models for long sequences. bioRxiv, pages 2023–06.
![]()
David Fitzek, Yi Hong Teoh, Hin Pok Fung, Gebremed- hin A Dagnew, Ejaaz Merali, M Schuyler Moss, Benjamin MacLellan, and Roger G Melko. 2024. Rydberggpt. arXiv preprint arXiv:2405.21052.
![]()
Daniel Flam-Shepherd and Alán Aspuru-Guzik. 2023. Language models can generate molecules, materials, and protein binding sites directly in three dimensions as xyz, cif, and pdb files. arXiv preprint arXiv:2305.05708.
![]()
Daniel Flam-Shepherd, Kevin Zhu, and Alán Aspuru- Guzik. 2022. Language models can learn complex molecular distributions. Nature Communications, 13(1):3293.
![]()
Oscar Franzén, Li-Ming Gan, and Johan LM Björkegren. 2019. Panglaodb: a web server for exploration of mouse and human single-cell rna sequencing data. Database, 2019:baz046.
![]()
Nathan C Frey, Ryan Soklaski, Simon Axelrod, Sid- dharth Samsi, Rafael Gomez-Bombarelli, Connor W Coley, and Vijay Gadepally. 2023. Neural scaling of deep chemical models. Nature Machine Intelligence, 5(11):1297–1305.

Anna Gaulton, Anne Hersey, Michał Nowotka, A Patricia Bento, Jon Chambers, David Mendez, Prudence Mutowo, Francis Atkinson, Louisa J Bellis, Elena Cibrián-Uhalte, et al. 2017. The chembl database in 2017. Nucleic Acids Research, 45(D1):D945–D954.
![]()
Mor Geva, Ankit Gupta, and Jonathan Berant. 2020. Injecting numerical reasoning skills into language models. In ACL’20, pages 946–958.
![]()
Shantanu Ghosh, Clare B Poynton, Shyam Visweswaran, and Kayhan Batmanghelich. 2024. Mammo-clip: A vision language foundation model to enhance data efficiency and robustness in mammography. arXiv preprint arXiv:2405.12255.
Michael Glass, Mustafa Canim, Alfio Gliozzo, Sa- neem Chemmengath, Vishwajeet Kumar, Rishav Chakravarti, Avirup Sil, Feifei Pan, Samarth Bharadwaj, and Nicolas Rodolfo Fauceglia. 2021. Capturing row and column semantics in transformer based question answering over tables. In NAACL’21, pages 1212–1224.
Jennifer Harrow, Adam Frankish, Jose M Gonzalez, Electra Tapanari, Mark Diekhans, Felix Kokocinski, Bronwen L Aken, Daniel Barrell, Amonida Zadissa, Stephen Searle, et al. 2012. Gencode: the reference human genome annotation for the encode project. Genome Research, 22(9):1760–1774.

Yuting He, Fuxiang Huang, Xinrui Jiang, Yuxiang Nie, Minghao Wang, Jiguang Wang, and Hao Chen. 2024b. Foundation model for advancing healthcare: Challenges, opportunities, and future directions. arXiv preprint arXiv:2404.03264.
Thorsten Hellert, João Montenegro, and Andrea Pol- lastro. 2024. Physbert: A text embedding model for physics scientific literature. arXiv preprint arXiv:2408.09574.

Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021b. Measuring mathematical problem solving with the math dataset. In NeurIPS’21.
![]()
Hans Hersbach, Bill Bell, Paul Berrisford, Shoji Hi- rahara, András Horányi, Joaquín Muñoz-Sabater, Julien Nicolas, Carole Peubey, Raluca Radu, Dinand Schepers, et al. 2020. The era5 global reanalysis. Quarterly Journal of the Royal Meteorological Society, 146(730):1999–2049.
![]()
Jonathan Herzig, Pawel Krzysztof Nowak, Thomas Mueller, Francesco Piccinno, and Julian Eisenschlos. 2020. Tapas: Weakly supervised table parsing via pre-training. In ACL’20, pages 4320–4333.
![]()
Brian Hie, Ellen D Zhong, Bonnie Berger, and Bryan Bryson. 2021. Learning the language of viral evolution and escape. Science, 371(6526):284–288.
![]()
Xanh Ho, Anh Khoa Duong Nguyen, An Tuan Dao, Jun- feng Jiang, Yuki Chida, Kaito Sugimoto, Huy Quoc To, Florian Boudin, and Akiko Aizawa. 2024. A survey of pre-trained language models for processing scientific text. arXiv preprint arXiv:2401.17824.
![]()
Zhi Hong, Aswathy Ajith, James Pauloski, Eamon Duede, Kyle Chard, and Ian Foster. 2023. The diminishing returns of masked language models to science. In Findings of ACL’23, pages 1270–1283.
![]()
Tom Hope, Aida Amini, David Wadden, Madeleine van Zuylen, Sravanthi Parasa, Eric Horvitz, Daniel S Weld, Roy Schwartz, and Hannaneh Hajishirzi. 2021.
Extracting a knowledge base of mechanisms from covid-19 papers. In NAACL’21, pages 4489–4503.
Wisdom Oluchi Ikezogwo, Mehmet Saygin Sey- fioglu, Fatemeh Ghezloo, Dylan Stefan Chan Geva, Fatwir Sheikh Mohammed, Pavan Kumar Anand, Ranjay Krishna, and Linda Shapiro. 2023. Quilt-1m: One million image-text pairs for histopathology. In NeurIPS’23.
Jeremy Irvin, Pranav Rajpurkar, Michael Ko, Yifan Yu, Silviana Ciurea-Ilcus, Chris Chute, Henrik Marklund, Behzad Haghgoo, Robyn Ball, Katie Shpanskaya, et al. 2019. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In AAAI’19, pages 590–597.
![]()
Ross Irwin, Spyridon Dimitriadis, Jiazhen He, and Esben Jannik Bjerrum. 2022. Chemformer: a pre-trained transformer for computational chemistry. Machine Learning: Science and Technology, 3(1):015022.
![]()
Kevin Maik Jablonka, Philippe Schwaller, Andres Ortega-Guerrero, and Berend Smit. 2024. Leveraging large language models for predictive chemistry. Nature Machine Intelligence, 6(2):161–169.
Anubhav Jain, Shyue Ping Ong, Geoffroy Hautier, Wei Chen, William Davidson Richards, Stephen Dacek, Shreyas Cholia, Dan Gunter, David Skinner, Gerbrand Ceder, et al. 2013. Commentary: The materials project: A materials genome approach to accelerating materials innovation. APL materials, 1(1).
Yanrong Ji, Zhihan Zhou, Han Liu, and Ramana V Davu- luri. 2021. Dnabert: pre-trained bidirectional encoder representations from transformers model for dnalanguage in genome. Bioinformatics, 37(15):2112– 2120.
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1–38.
![]()
Zhengbao Jiang, Yi Mao, Pengcheng He, Graham Neu- big, and Weizhu Chen. 2022. Omnitab: Pretraining with natural and synthetic data for few-shot tablebased question answering. In NAACL’22, pages 932– 942.
![]()
Zhanming Jie, Jierui Li, and Wei Lu. 2022. Learning to reason deductively: Math word problem solving as complex relation extraction. In ACL’22, pages 5944–5955.
Bowen Jin, Gang Liu, Chi Han, Meng Jiang, Heng Ji, and Jiawei Han. 2023a. Large language models on graphs: A comprehensive survey. arXiv preprint arXiv:2312.02783.
![]()
Bowen Jin, Chulin Xie, Jiawei Zhang, Kashob Ku- mar Roy, Yu Zhang, Zheng Li, Ruirui Li, Xianfeng Tang, Suhang Wang, Yu Meng, and Jiawei Han. 2024. Graph chain-of-thought: Augmenting large language models by reasoning on graphs. In Findings of ACL’24, pages 163–184.
Sunghwan Kim, Jie Chen, Tiejun Cheng, Asta Gindu- lyte, Jia He, Siqian He, Qingliang Li, Benjamin A Shoemaker, Paul A Thiessen, Bo Yu, et al. 2019. Pubchem 2019 update: improved access to chemical data. Nucleic Acids Research, 47(D1):D1102–D1109.
![]()
Thomas N Kipf and Max Welling. 2017. Semisupervised classification with graph convolutional networks. In AAAI’17.
![]()
Mario Krenn, Florian Häse, AkshatKumar Nigam, Pas- cal Friederich, and Alan Aspuru-Guzik. 2020. Selfreferencing embedded strings (selfies): A 100% robust molecular string representation. Machine Learning: Science and Technology, 1(4):045024.
![]()
Christopher Kuenneth and Rampi Ramprasad. 2023. polybert: a chemical language model to enable fully machine-driven ultrafast polymer informatics. Nature Communications, 14(1):4099.
![]()
Avan Kumar, Bhavik R Bakshi, Manojkumar Ramteke, and Hariprasad Kodamana. 2023. Recycle-bert: extracting knowledge about plastic waste recycling by natural language processing. ACS Sustainable Chemistry & Engineering, 11(32):12123–12134.
![]()
Yanis Labrak, Adrien Bazoge, Emmanuel Morin, Pierre- Antoine Gourraud, Mickael Rouvier, and Richard Dufour. 2024. Biomistral: A collection of open-source pretrained large language models for medical domains. In Findings of ACL’24, pages 5848–5864.
![]()
Dan Lahav, Jon Saad Falcon, Bailey Kuehl, Sophie John- son, Sravanthi Parasa, Noam Shomron, Duen Horng Chau, Diyi Yang, Eric Horvitz, Daniel S Weld, et al. 2022. A search engine for discovery of scientific challenges and directions. In AAAI’22, pages 11982– 11990.
![]()
Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. 2020. Biobert: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics, 36(4):1234–1240.
![]()
Oliver Lehmberg, Dominique Ritze, Robert Meusel, and Christian Bizer. 2016. A large public corpus of web tables containing time and context metadata. In WWW’16, pages 75–76.
![]()
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020a. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In ACL’20, pages 7871–7880.
![]()
Patrick Lewis, Myle Ott, Jingfei Du, and Veselin Stoy- anov. 2020b. Pretrained language models for biomedical and clinical tasks: understanding and extending the state-of-the-art. In Proceedings of the 3rd Clinical Natural Language Processing Workshop, pages 146–157.
Zekun Li, Jina Kim, Yao-Yi Chiang, and Muhao Chen. 2022b. Spabert: A pretrained language model from geographic data for geo-entity representation. In Findings of EMNLP’22, pages 2757–2769.
![]()
Zekun Li, Wenxuan Zhou, Yao-Yi Chiang, and Muhao Chen. 2023f. Geolm: Empowering language models for geospatially grounded language understanding. In EMNLP’23, pages 5227–5240.
Zhongli Li, Wenxuan Zhang, Chao Yan, Qingyu Zhou, Chao Li, Hongzhi Liu, and Yunbo Cao. 2022c. Seeking patterns, not just memorizing procedures: Contrastive learning for solving math word problems. In Findings of ACL’22, pages 2486–2496.
![]()
Weixin Liang, Zachary Izzo, Yaohui Zhang, Haley Lepp, Hancheng Cao, Xuandong Zhao, Lingjiao Chen, Haotian Ye, Sheng Liu, Zhi Huang, et al. 2024a. Monitoring ai-modified content at scale: A case study on the impact of chatgpt on ai conference peer reviews. In ICML’24.
![]()
Weixin Liang, Yaohui Zhang, Zhengxuan Wu, Haley Lepp, Wenlong Ji, Xuandong Zhao, Hancheng Cao, Sheng Liu, Siyu He, Zhi Huang, et al. 2024b. Mapping the increasing use of llms in scientific papers. arXiv preprint arXiv:2404.01268.
![]()
Weixin Liang, Yuhui Zhang, Hancheng Cao, Binglu Wang, Daisy Yi Ding, Xinyu Yang, Kailas Vodrahalli, Siyu He, Daniel Scott Smith, Yian Yin, et al. 2024c. Can large language models provide useful feedback on research papers? a large-scale empirical analysis. NEJM AI, 1(8):AIoa2400196.
![]()
Zhenwen Liang, Kehan Guo, Gang Liu, Taicheng Guo, Yujun Zhou, Tianyu Yang, Jiajun Jiao, Renjie Pi, Jipeng Zhang, and Xiangliang Zhang. 2024d. Scemqa: A scientific college entrance level multi-modal question answering benchmark. In ACL’24, pages 109–119.
![]()
Zhenwen Liang, Tianyu Yang, Jipeng Zhang, and Xian- gliang Zhang. 2023. Unimath: A foundational and multimodal mathematical reasoner. In EMNLP’23, pages 7126–7133.
Zhenwen Liang, Jipeng Zhang, Lei Wang, Wei Qin, Yunshi Lan, Jie Shao, and Xiangliang Zhang. 2022. Mwp-bert: Numeracy-augmented pre-training for math word problem solving. In Findings of NAACL’22, pages 997–1009.
Jiacheng Lin, Hanwen Xu, Zifeng Wang, Sheng Wang, and Jimeng Sun. 2024a. Panacea: A foundation model for clinical trial search, summarization, design, and recruitment. arXiv preprint arXiv:2407.11007.
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. 2017. Focal loss for dense object detection. In ICCV’17, pages 2980–2988.
Shengchao Liu, Yanjing Li, Zhuoxinran Li, Anthony Gitter, Yutao Zhu, Jiarui Lu, Zhao Xu, Weili Nie, Arvind Ramanathan, Chaowei Xiao, et al. 2023c. A text-guided protein design framework. arXiv preprint arXiv:2302.04611.
Shengchao Liu, Weili Nie, Chengpeng Wang, Jiarui Lu, Zhuoran Qiao, Ling Liu, Jian Tang, Chaowei Xiao, and Animashree Anandkumar. 2023d. Multimodal molecule structure–text model for text-based retrieval and editing. Nature Machine Intelligence, 5(12):1447–1457.
Shengchao Liu, Jiongxiao Wang, Yijin Yang, Cheng- peng Wang, Ling Liu, Hongyu Guo, and Chaowei Xiao. 2024b. Conversational drug editing using retrieval and domain feedback. In ICLR’24.
Xiao Liu, Da Yin, Jingnan Zheng, Xingjian Zhang, Peng Zhang, Hongxia Yang, Yuxiao Dong, and Jie Tang. 2022b. Oag-bert: Towards a unified backbone language model for academic knowledge services. In KDD’22, pages 3418–3428.
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Man- dar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
![]()
Zhiyuan Liu, Sihang Li, Yanchen Luo, Hao Fei, Yixin Cao, Kenji Kawaguchi, Xiang Wang, and Tat-Seng Chua. 2023e. Molca: Molecular graph-language modeling with cross-modal projector and uni-modal adapter. In EMNLP’23, pages 15623–15638.
![]()
Kyle Lo, Lucy Lu Wang, Mark Neumann, Rodney Kin- ney, and Daniel S Weld. 2020. S2orc: The semantic scholar open research corpus. In ACL’20, pages 4969–4983.
Jieyu Lu and Yingkai Zhang. 2022. Unified deep learn- ing model for multitask reaction predictions with explanation. Journal of Chemical Information and Modeling, 62(6):1376–1387.
![]()
Ming Y Lu, Bowen Chen, Andrew Zhang, Drew FK Williamson, Richard J Chen, Tong Ding, Long Phi Le, Yung-Sung Chuang, and Faisal Mahmood. 2023. Visual language pretrained multiple instance zero-shot transfer for histopathology images. In CVPR’23, pages 19764–19775.
![]()
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chun- yuan Li, Hannaneh Hajishirzi, Hao Cheng, KaiWei Chang, Michel Galley, and Jianfeng Gao. 2024. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. In ICLR’24.
![]()
Pan Lu, Ran Gong, Shibiao Jiang, Liang Qiu, Siyuan Huang, Xiaodan Liang, and Song-chun Zhu. 2021. Inter-gps: Interpretable geometry problem solving with formal language and symbolic reasoning. In ACL’21, pages 6774–6786.
Łukasz Maziarka, Dawid Majchrowski, Tomasz Danel, Piotr Gai´nski, Jacek Tabor, Igor Podolak, Paweł Morkisz, and Stanisław Jastrz˛ebski. 2024. Relative molecule self-attention transformer. Journal of Cheminformatics, 16(1):3.
![]()
Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu, and Alex Rives. 2021. Language models enable zero-shot prediction of the effects of mutations on protein function. In NeurIPS’21, pages 29287– 29303.
![]()
Yiwen Meng, William Speier, Michael K Ong, and Corey W Arnold. 2021a. Bidirectional representation learning from transformers using multimodal electronic health record data to predict depression. IEEE Journal of Biomedical and Health Informatics, 25(8):3121–3129.
![]()
Zaiqiao Meng, Fangyu Liu, Thomas Clark, Ehsan Shareghi, and Nigel Collier. 2021b. Mixture-of-partitions: Infusing large biomedical knowledge graphs into bert. In EMNLP’21, pages 4672–4681.
![]()
Giacomo Miolo, Giulio Mantoan, and Carlotta Orsenigo. 2021. Electramed: a new pre-trained language representation model for biomedical nlp. arXiv preprint arXiv:2104.09585.
![]()
Adrian Mirza, Nawaf Alampara, Sreekanth Kunchapu, Benedict Emoekabu, Aswanth Krishnan, Mara Wilhelmi, Macjonathan Okereke, Juliane Eberhardt, Amir Mohammad Elahi, Maximilian Greiner, et al. 2024. Are large language models superhuman chemists? arXiv preprint arXiv:2404.01475.
![]()
Swaroop Mishra, Matthew Finlayson, Pan Lu, Leonard Tang, Sean Welleck, Chitta Baral, Tanmay Rajpurohit, Oyvind Tafjord, Ashish Sabharwal, Peter Clark, et al. 2022. Lila: A unified benchmark for mathematical reasoning. In EMNLP’22, pages 5807–5832.
![]()
Jong Hak Moon, Hyungyung Lee, Woncheol Shin, Young-Hak Kim, and Edward Choi. 2022. Multimodal understanding and generation for medical images and text via vision-language pre-training. IEEE JBHI, 26(12):6070–6080.
![]()
Michael Moor, Qian Huang, Shirley Wu, Michihiro Yasunaga, Yash Dalmia, Jure Leskovec, Cyril Zakka, Eduardo Pontes Reis, and Pranav Rajpurkar. 2023. Med-flamingo: a multimodal medical few-shot learner. In ML4H’23, pages 353–367.
![]()
S Mostafa Mousavi, William L Ellsworth, Weiqiang Zhu, Lindsay Y Chuang, and Gregory C Beroza. 2020. Earthquake transformer—an attentive deep-learning model for simultaneous earthquake detection and phase picking. Nature Communications, 11(1):3952.
Martin Müller, Marcel Salathé, and Per E Kummervold. 2023. Covid-twitter-bert: A natural language processing model to analyse covid-19 content on twitter. Frontiers in Artificial Intelligence, 6:1023281.
Ibrahim Burak Ozyurt. 2020. On the effectiveness of small, discriminatively pre-trained language representation models for biomedical text mining. In Proceedings of the First Workshop on Scholarly Document Processing, pages 104–112.

Panupong Pasupat and Percy Liang. 2015. Compositional semantic parsing on semi-structured tables. In ACL’15, pages 1470–1480.
![]()
Jaideep Pathak, Shashank Subramanian, Peter Harring- ton, Sanjeev Raja, Ashesh Chattopadhyay, Morteza Mardani, Thorsten Kurth, David Hall, Zongyi Li, Kamyar Azizzadenesheli, et al. 2022. Fourcastnet: A global data-driven high-resolution weather model using adaptive fourier neural operators. arXiv preprint arXiv:2202.11214.
Qizhi Pei, Lijun Wu, Kaiyuan Gao, Jinhua Zhu, Yue Wang, Zun Wang, Tao Qin, and Rui Yan. 2024. Leveraging biomolecule and natural language through multi-modal learning: A survey. arXiv preprint arXiv:2403.01528.
![]()
Qizhi Pei, Wei Zhang, Jinhua Zhu, Kehan Wu, Kaiyuan Gao, Lijun Wu, Yingce Xia, and Rui Yan. 2023. Biot5: Enriching cross-modal integration in biology with chemical knowledge and natural language associations. In EMNLP’23, pages 1102–1123.
![]()
Obioma Pelka, Sven Koitka, Johannes Rückert, Felix Nensa, and Christoph M Friedrich. 2018. Radiology objects in context (roco): a multimodal image dataset. In 7th Joint International Workshop, CVII-STENT and 3rd International Workshop, LABELS, Held in Conjunction with MICCAI’18, pages 180–189.
Chantal Pellegrini, Matthias Keicher, Ege Özsoy, Petra Jiraskova, Rickmer Braren, and Nassir Navab. 2023. Xplainer: From x-ray observations to explainable zero-shot diagnosis. In MICCAI’23, pages 420–429. Springer.
Yifan Peng, Shankai Yan, and Zhiyong Lu. 2019. Trans- fer learning in biomedical natural language processing: An evaluation of bert and elmo on ten benchmarking datasets. In Proceedings of the 18th BioNLP Workshop and Shared Task, pages 58–65.
Ernest Perkowski, Rui Pan, Tuan Dung Nguyen, Yuan- Sen Ting, Sandor Kruk, Tong Zhang, Charlie O’Neill, Maja Jablonska, Zechang Sun, Michael J Smith, et al. 2024. Astrollama-chat: Scaling astrollama with conversational and diverse datasets. Research Notes of the AAS, 8(1):7.
![]()
Long N Phan, James T Anibal, Hieu Tran, Shaurya Chanana, Erol Bahadroglu, Alec Peltekian, and Gré-goire Altan-Bonnet. 2021. Scifive: a text-to-text transformer model for biomedical literature. arXiv preprint arXiv:2106.03598.
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M Pawan Kumar, Emilien Dupont, Francisco JR Ruiz, Jordan S Ellenberg, Pengming Wang, Omar Fawzi, et al. 2024. Mathematical discoveries from program search with large language models. Nature, 625(7995):468–475.
![]()
Jerret Ross, Brian Belgodere, Vijil Chenthamarakshan, Inkit Padhi, Youssef Mroueh, and Payel Das. 2022. Large-scale chemical language representations capture molecular structure and properties. Nature Machine Intelligence, 4(12):1256–1264.
![]()
Andre Niyongabo Rubungo, Craig Arnold, Barry P Rand, and Adji Bousso Dieng. 2023. Llm-prop: Predicting physical and electronic properties of crystalline solids from their text descriptions. arXiv preprint arXiv:2310.14029.
![]()
Khaled Saab, Tao Tu, Wei-Hung Weng, Ryutaro Tanno, David Stutz, Ellery Wulczyn, Fan Zhang, Tim Strother, Chunjong Park, Elahe Vedadi, et al. 2024. Capabilities of gemini models in medicine. arXiv preprint arXiv:2404.18416.
Tobias Schimanski, Julia Bingler, Mathias Kraus, Camilla Hyslop, and Markus Leippold. 2023. Climatebert-netzero: Detecting and assessing net zero and reduction targets. In EMNLP’23, pages 15745–15756.
![]()
Nadine Schneider, Nikolaus Stiefl, and Gregory A Lan- drum. 2016. What’s what: The (nearly) definitive guide to reaction role assignment. Journal of Chemical Information and Modeling, 56(12):2336–2346.
![]()
Philippe Schwaller, Benjamin Hoover, Jean-Louis Rey- mond, Hendrik Strobelt, and Teodoro Laino. 2021a. Extraction of organic chemistry grammar from unsupervised learning of chemical reactions. Science Advances, 7(15):eabe4166.
Philippe Schwaller, Daniel Probst, Alain C Vaucher, Vishnu H Nair, David Kreutter, Teodoro Laino, and Jean-Louis Reymond. 2021b. Mapping the space of chemical reactions using attention-based neural networks. Nature Machine Intelligence, 3(2):144– 152.
![]()
Minjoon Seo, Hannaneh Hajishirzi, Ali Farhadi, Oren Etzioni, and Clint Malcolm. 2015. Solving geometry problems: Combining text and diagram interpretation. In EMNLP’15, pages 1466–1476.

Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, YK Li, Y Wu, and Daya Guo. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300.
Henry W Sprueill, Carl Edwards, Khushbu Agarwal, Mariefel V Olarte, Udishnu Sanyal, Conrad Johnston, Hongbin Liu, Heng Ji, and Sutanay Choudhury. 2024. Chemreasoner: Heuristic search over a large language model’s knowledge space using quantum-chemical feedback. In ICML’24, pages 46351–46374.
![]()
Teague Sterling and John J Irwin. 2015. Zinc 15–ligand discovery for everyone. Journal of Chemical Information and Modeling, 55(11):2324–2337.
![]()
Samuel Stevens, Jiaman Wu, Matthew J Thompson, Elizabeth G Campolongo, Chan Hee Song, David Edward Carlyn, Li Dong, Wasila M Dahdul, Charles Stewart, Tanya Berger-Wolf, et al. 2024. Bioclip: A vision foundation model for the tree of life. In CVPR’24, pages 19412–19424.
![]()
Bing Su, Dazhao Du, Zhao Yang, Yujie Zhou, Jiang- meng Li, Anyi Rao, Hao Sun, Zhiwu Lu, and JiRong Wen. 2022. A molecular multimodal foundation model associating molecule graphs with natural language. arXiv preprint arXiv:2209.05481.
Jin Su, Chenchen Han, Yuyang Zhou, Junjie Shan, Xibin Zhou, and Fajie Yuan. 2024. Saprot: protein language modeling with structure-aware vocabulary. In ICLR’24.
Sanjay Subramanian, Lucy Lu Wang, Sachin Mehta, Ben Bogin, Madeleine van Zuylen, Sravanthi Parasa, Sameer Singh, Matt Gardner, and Hannaneh Hajishirzi. 2020. Medicat: A dataset of medical images, captions, and textual references. In Findings of EMNLP’20, pages 2112–2120.
![]()
Baris E Suzek, Yuqi Wang, Hongzhan Huang, Peter B McGarvey, Cathy H Wu, and UniProt Consortium. 2015. Uniref clusters: a comprehensive and scalable alternative for improving sequence similarity searches. Bioinformatics, 31(6):926–932.
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Se- bastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc Le, Ed Chi, Denny Zhou, et al. 2023. Challenging big-bench tasks and whether chain-of-thought can solve them. In Findings of ACL’23, pages 13003–13051.
![]()
Jie Tang, Jing Zhang, Limin Yao, Juanzi Li, Li Zhang, and Zhong Su. 2008. Arnetminer: extraction and mining of academic social networks. In KDD’08, pages 990–998.
Tim Tanida, Philip Müller, Georgios Kaissis, and Daniel Rueckert. 2023. Interactive and explainable regionguided radiology report generation. In CVPR’23, pages 7433–7442.
Ross Taylor, Marcin Kardas, Guillem Cucurull, Thomas Scialom, Anthony Hartshorn, Elvis Saravia, Andrew Poulton, Viktor Kerkez, and Robert Stojnic. 2022. Galactica: A large language model for science. arXiv preprint arXiv:2211.09085.
Ellen Voorhees, Tasmeer Alam, Steven Bedrick, Dina Demner-Fushman, William R Hersh, Kyle Lo, Kirk Roberts, Ian Soboroff, and Lucy Lu Wang. 2021. Trec-covid: constructing a pandemic information retrieval test collection. SIGIR Forum, 54(1):1–12.
Shoya Wada, Toshihiro Takeda, Shiro Manabe, Shozo Konishi, Jun Kamohara, and Yasushi Matsumura. 2020. Pre-training technique to localize medical bert and enhance biomedical bert. arXiv preprint arXiv:2005.07202.
Zhongwei Wan, Che Liu, Mi Zhang, Jie Fu, Benyou Wang, Sibo Cheng, Lei Ma, César Quilodrán-Casas, and Rossella Arcucci. 2023. Med-unic: Unifying cross-lingual medical vision-language pre-training by diminishing bias. In NeurIPS’23.
Benyou Wang, Qianqian Xie, Jiahuan Pei, Zhihong Chen, Prayag Tiwari, Zhao Li, and Jie Fu. 2023a. Pretrained language models in biomedical domain: A systematic survey. ACM Computing Surveys, 56(3):1– 52.
Dongjie Wang, Chang-Tien Lu, and Yanjie Fu. 2023b. Towards automated urban planning: When generative and chatgpt-like ai meets urban planning. arXiv preprint arXiv:2304.03892.
Fuying Wang, Yuyin Zhou, Shujun Wang, Varut Vard- hanabhuti, and Lequan Yu. 2022a. Multi-granularity cross-modal alignment for generalized medical visual representation learning. In NeurIPS’22, pages 33536–33549.
Hanchen Wang, Tianfan Fu, Yuanqi Du, Wenhao Gao, Kexin Huang, Ziming Liu, Payal Chandak, Shengchao Liu, Peter Van Katwyk, Andreea Deac, et al. 2023c. Scientific discovery in the age of artificial intelligence. Nature, 620(7972):47–60.
![]()
Hanyin Wang, Chufan Gao, Christopher Dantona, Bryan Hull, and Jimeng Sun. 2024a. Drg-llama: tuning llama model to predict diagnosis-related group for hospitalized patients. npj Digital Medicine, 7(1):16.
Haochun Wang, Chi Liu, Nuwa Xi, Zewen Qiang, Sendong Zhao, Bing Qin, and Ting Liu. 2023d. Huatuo: Tuning llama model with chinese medical knowledge. arXiv preprint arXiv:2304.06975.
Haorui Wang, Marta Skreta, Cher-Tian Ser, Wenhao Gao, Lingkai Kong, Felix Streith-Kalthoff, Chenru Duan, Yuchen Zhuang, Yue Yu, Yanqiao Zhu, et al. 2024b. Efficient evolutionary search over chemical space with large language models. arXiv preprint arXiv:2406.16976.
![]()
Ke Wang, Houxing Ren, Aojun Zhou, Zimu Lu, Sichun Luo, Weikang Shi, Renrui Zhang, Linqi Song, Mingjie Zhan, and Hongsheng Li. 2024c. Mathcoder: Seamless code integration in llms for enhanced mathematical reasoning. In ICLR’24.
David Weininger. 1988. Smiles, a chemical language and information system. 1. introduction to methodology and encoding rules. Journal of Chemical Information and Computer Sciences, 28(1):31–36.
Johannes Welbl, Nelson F Liu, and Matt Gardner. 2017. Crowdsourcing multiple choice science questions. In Proceedings of the 3rd Workshop on Noisy Usergenerated Text, pages 94–106.
Sean Welleck, Jiacheng Liu, Ximing Lu, Hannaneh Hajishirzi, and Yejin Choi. 2022. Naturalprover: Grounded mathematical proof generation with language models. In NeurIPS’22, pages 4913–4927.
![]()
Hongzhi Wen, Wenzhuo Tang, Xinnan Dai, Jiayuan Ding, Wei Jin, Yuying Xie, and Jiliang Tang. 2024. Cellplm: Pre-training of cell language model beyond single cells. In ICLR’24.
![]()
Andrew D White. 2023. The future of chemistry is language. Nature Reviews Chemistry, 7(7):457–458.
![]()
Chaoyi Wu, Weixiong Lin, Xiaoman Zhang, Ya Zhang, Weidi Xie, and Yanfeng Wang. 2024. Pmc-llama: toward building open-source language models for medicine. JAMIA, 31(9):1833–1843.
![]()
Chaoyi Wu, Xiaoman Zhang, Ya Zhang, Yanfeng Wang, and Weidi Xie. 2023. Towards generalist foundation model for radiology. arXiv preprint arXiv:2308.02463.
![]()
Zhenqin Wu, Bharath Ramsundar, Evan N Feinberg, Joseph Gomes, Caleb Geniesse, Aneesh S Pappu, Karl Leswing, and Vijay Pande. 2018. Moleculenet: a benchmark for molecular machine learning. Chemical Science, 9(2):513–530.

Qianqian Xie, Qingyu Chen, Aokun Chen, Cheng Peng, Yan Hu, Fongci Lin, Xueqing Peng, Jimin Huang, Jeffrey Zhang, Vipina Keloth, et al. 2024. Me llama: Foundation large language models for medical applications. arXiv preprint arXiv:2402.12749.
![]()
Tong Xie, Yuwei Wan, Wei Huang, Zhenyu Yin, Yixuan Liu, Shaozhou Wang, Qingyuan Linghu, Chunyu Kit, Clara Grazian, Wenjie Zhang, et al. 2023. Darwin series: Domain specific large language models for natural science. arXiv preprint arXiv:2308.13565.
![]()
Guangzhi Xiong, Qiao Jin, Zhiyong Lu, and Aidong Zhang. 2024. Benchmarking retrieval-augmented generation for medicine. In Findings of ACL’24, pages 6233–6251.
![]()
Honglin Xiong, Sheng Wang, Yitao Zhu, Zihao Zhao, Yuxiao Liu, Linlin Huang, Qian Wang, and Dinggang Shen. 2023. Doctorglm: Fine-tuning your chinese doctor is not a herculean task. arXiv preprint arXiv:2304.01097.
Zonglin Yang, Xinya Du, Junxian Li, Jie Zheng, Sou- janya Poria, and Erik Cambria. 2024d. Large language models for automated open-domain scientific hypotheses discovery. In Findings of ACL’24, pages 13545–13565.
![]()
Michihiro Yasunaga, Antoine Bosselut, Hongyu Ren, Xikun Zhang, Christopher D Manning, Percy S Liang, and Jure Leskovec. 2022a. Deep bidirectional language-knowledge graph pretraining. In NeurIPS’22, pages 37309–37323.
![]()
Michihiro Yasunaga, Jure Leskovec, and Percy Liang. 2022b. Linkbert: Pretraining language models with document links. In ACL’22, pages 8003–8016.
Geyan Ye, Xibao Cai, Houtim Lai, Xing Wang, Jun- hong Huang, Longyue Wang, Wei Liu, and Xiangxiang Zeng. 2023a. Drugassist: A large language model for molecule optimization. arXiv preprint arXiv:2401.10334.
Qichen Ye, Junling Liu, Dading Chong, Peilin Zhou, Yining Hua, and Andrew Liu. 2023b. Qilinmed: Multi-stage knowledge injection advanced medical large language model. arXiv preprint arXiv:2310.09089.
![]()
Junqi Yin, Sajal Dash, Feiyi Wang, and Mallikarjun Shankar. 2023. Forge: pre-training open foundation models for science. In SC’23, pages 1–13.
![]()
Pengcheng Yin, Graham Neubig, Wen-tau Yih, and Se- bastian Riedel. 2020. Tabert: Pretraining for joint understanding of textual and tabular data. In ACL’20, pages 8413–8426.
Huaiyuan Ying, Shuo Zhang, Linyang Li, Zhejian Zhou, Yunfan Shao, Zhaoye Fei, Yichuan Ma, Jiawei Hong, Kuikun Liu, Ziyi Wang, et al. 2024. Internlm-math: Open math large language models toward verifiable reasoning. arXiv preprint arXiv:2402.06332.
Kihyun You, Jawook Gu, Jiyeon Ham, Beomhee Park, Jiho Kim, Eun K Hong, Woonhyuk Baek, and Byungseok Roh. 2023. Cxr-clip: Toward large scale chest x-ray language-image pre-training. In MICCAI’23, pages 101–111.
![]()
Botao Yu, Frazier N Baker, Ziqi Chen, Xia Ning, and Huan Sun. 2024a. Llasmol: Advancing large language models for chemistry with a large-scale, comprehensive, high-quality instruction tuning dataset. arXiv preprint arXiv:2402.09391.
Fei Yu, Anningzhe Gao, and Benyou Wang. 2024b. Ovm, outcome-supervised value models for planning in mathematical reasoning. In Findings of NAACL’24, pages 858–875.
![]()
Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. 2024c. Metamath: Bootstrap your own mathematical questions for large language models. In ICLR’24.
Hongbo Zhang, Junying Chen, Feng Jiang, Fei Yu, Zhi- hong Chen, Guiming Chen, Jianquan Li, Xiangbo Wu, Zhang Zhiyi, Qingying Xiao, et al. 2023b. Huatuogpt, towards taming language model to be a doctor. In Findings of EMNLP’23, pages 10859–10885.
Kai Zhang, Rong Zhou, Eashan Adhikarla, Zhiling Yan, Yixin Liu, Jun Yu, Zhengliang Liu, Xun Chen, Brian D Davison, Hui Ren, et al. 2024c. A generalist vision–language foundation model for diverse biomedical tasks. Nature Medicine, pages 1–13.
Ningyu Zhang, Qianghuai Jia, Kangping Yin, Liang Dong, Feng Gao, and Nengwei Hua. 2020. Conceptualized representation learning for chinese biomedical text mining. arXiv preprint arXiv:2008.10813.
![]()
Qiang Zhang, Keyang Ding, Tianwen Lyv, Xinda Wang, Qingyu Yin, Yiwen Zhang, Jing Yu, Yuhao Wang, Xiaotong Li, Zhuoyi Xiang, et al. 2024d. Scientific large language models: A survey on biological & chemical domains. arXiv preprint arXiv:2401.14656.
![]()
Sheng Zhang, Yanbo Xu, Naoto Usuyama, Hanwen Xu, Jaspreet Bagga, Robert Tinn, Sam Preston, Rajesh Rao, Mu Wei, Naveen Valluri, et al. 2023c. Biomedclip: a multimodal biomedical foundation model pre-trained from fifteen million scientific image-text pairs. arXiv preprint arXiv:2303.00915.
![]()
Tianshu Zhang, Xiang Yue, Yifei Li, and Huan Sun. 2024e. Tablellama: Towards open large generalist models for tables. In NAACL’24, pages 6024–6044.
![]()
Xiaokang Zhang, Jing Zhang, Zeyao Ma, Yang Li, Bohan Zhang, Guanlin Li, Zijun Yao, Kangli Xu, Jinchang Zhou, Daniel Zhang-Li, et al. 2024f. Tablellm: Enabling tabular data manipulation by llms in real office usage scenarios. arXiv preprint arXiv:2403.19318.
![]()
Xinlu Zhang, Chenxin Tian, Xianjun Yang, Lichang Chen, Zekun Li, and Linda Ruth Petzold. 2023d. Alpacare: Instruction-tuned large language models for medical application. arXiv preprint arXiv:2310.14558.
![]()
Xuan Zhang, Limei Wang, Jacob Helwig, Youzhi Luo, Cong Fu, Yaochen Xie, Meng Liu, Yuchao Lin, Zhao Xu, Keqiang Yan, et al. 2023e. Artificial intelligence for science in quantum, atomistic, and continuum systems. arXiv preprint arXiv:2307.08423.
![]()
Yikun Zhang, Mei Lang, Jiuhong Jiang, Zhiqiang Gao, Fan Xu, Thomas Litfin, Ke Chen, Jaswinder Singh, Xiansong Huang, Guoli Song, et al. 2024g. Multiple sequence alignment-based rna language model and its application to structural inference. Nucleic Acids Research, 52(1):e3–e3.
Yu Zhang, Hao Cheng, Zhihong Shen, Xiaodong Liu, Ye-Yi Wang, and Jianfeng Gao. 2023f. Pre-training multi-task contrastive learning models for scientific literature understanding. In Findings of EMNLP’23, pages 12259–12275.
Victor Zhong, Caiming Xiong, and Richard Socher. 2017. Seq2sql: Generating structured queries from natural language using reinforcement learning. arXiv preprint arXiv:1709.00103.

Maxim Zvyagin, Alexander Brace, Kyle Hippe, Yuntian Deng, Bin Zhang, Cindy Orozco Bohorquez, Austin Clyde, Bharat Kale, Danilo Perez-Rivera, Heng Ma, et al. 2023. Genslms: Genome-scale language models reveal sars-cov-2 evolutionary dynamics. The International Journal of High Performance Computing Applications, 37(6):683–705.

Table A1-Table A6 summarize the modality, number of parameters, model architecture, pre-training data, pre-training task(s), and evaluation task(s) of scientific LLMs in each field. Within each field, we categorize models according to their modality; within each modality, we sort models chronologically. To be specific, if a paper has a preprint (e.g., arXiv or bioRxiv) version, its publication date is according to the preprint service. Otherwise, its publication date is according to the conference proceeding or journal.
Table A2: Summary of LLMs in mathematics. “L+V”: Language + Vision; “MWP”: math word problems. Other notations have the same meaning as in previous tables.
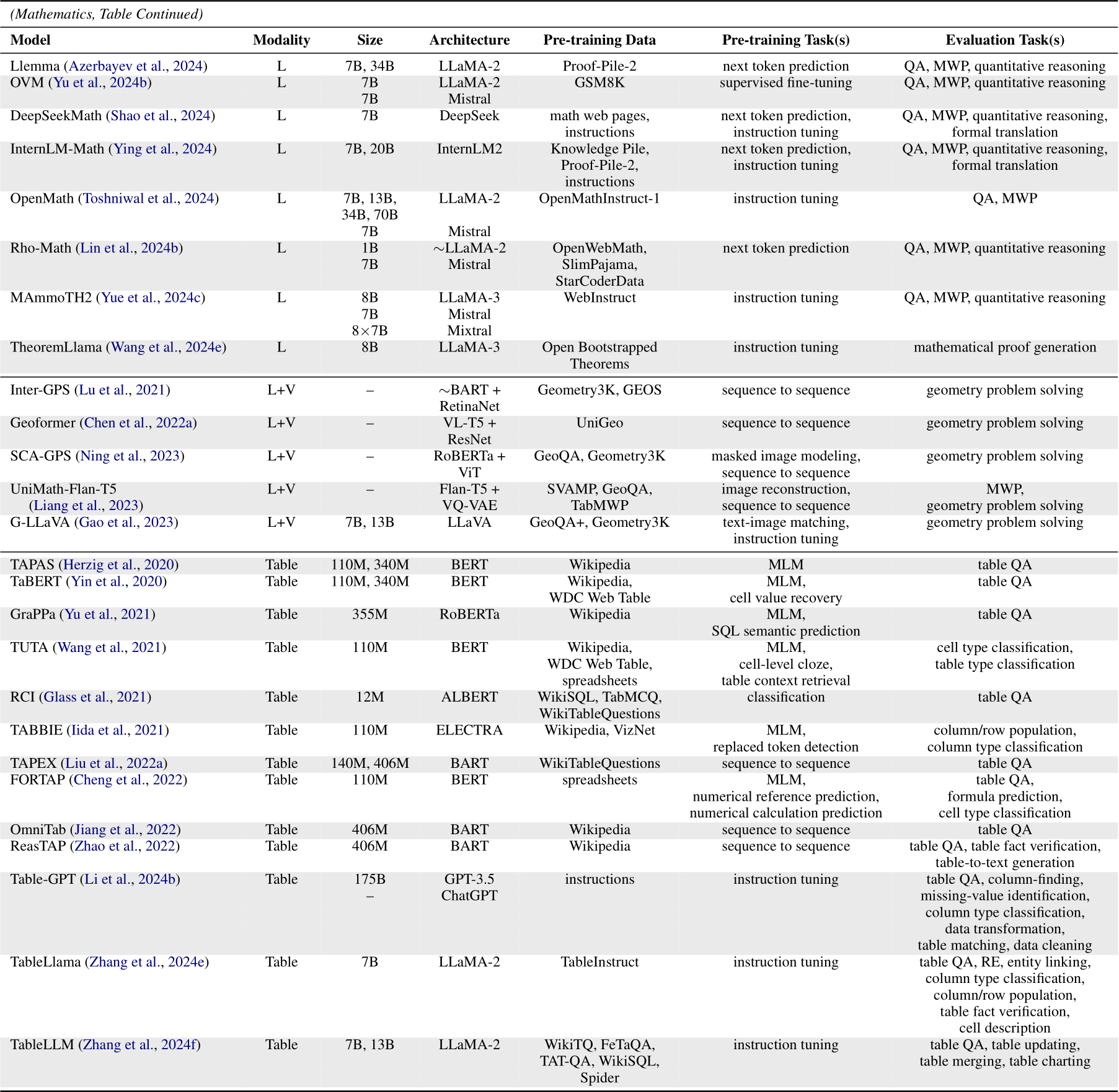
Table A3: Summary of LLMs in physics. Notations have the same meaning as in previous tables.
Table A4: Summary of LLMs in chemistry and materials science. “L+G+V”: Language + Graph + Vision; “KG”: knowledge graph; “SMILES”: simplified molecular-input line-entry system. Other notations have the same meaning as in previous tables.